View source for Talk:XanderCat
Congrats on breaking the 50% barrier. Seems that you have the planning of your bot on scheme, now it's just the translation into the right code. One small remark: You don't have to have 'zillions of versions' present in the rumble, the details of older versions still are available when not in the participants list anymore. Comparisons between two versions are quite easy to do like [1] . Just click on your bot in the rankings, then the details and a few older versions are shown. Good luck with your further development! --GrubbmGait 08:37, 25 May 2011 (UTC)
- Thanks GrubbmGait, though I'm not sure how much praise I deserve for being officially average. :-P I'm trying out a slightly revised version today, version 2.1. No major component changes, but it modifies the bullet firing parameters, driving parameters, some segmentation parameters, and has improved gun selection. Skotty 20:43, 25 May 2011 (UTC)
Contents
- 1 Rethink / XanderCat 4.8+
- 2 Case Analysis
- 3 Which Waves to Surf
- 4 Rolling Average
- 5 #1 Against PolishedRuby
- 6 Fixing My Wave Surfing Rolling Depth
- 7 Might have to get back into things
- 8 Version 6.x Scores All Over The Map
- 9 New Theory on Performance Issues
- 10 Debugging XanderCat -- What Next?
- 11 Empty Output Files
- 12 New Factor Array Idea
- 13 Next Plans -- XanderCat 9.x -- September, 2011
- 14 New Segmenter
- 15 Version 9.5 - Interesting Results
- 16 Melee Rumble
- 17 Best Bot Page Candidate
- 18 KD-Tree
Rethink / XanderCat 4.8+
I lost some ranks when I refactored the guess factor and wave surfing code in version 4.7, and have yet to get them back. But I'm still convinced the refactor was a good thing.
I've ironed out all the major bugs, and if I watch XanderCat in some battles, I don't see it doing anything obviously wrong. This got me thinking about how I handle segmentation again. I think my philosophy on balancing segments for comparison was wrong in the drive, and am changing it in version 4.8. I also plan on excluding certain segment combinations that when I think about them, just don't make much sense (like using just opponent velocity). I think this should improve performance.
Beyond this, I'm not sure what I would do next to try to improve. I could run zillions of combinations of segments and parameters just to see what seems to work better against a large groups of robots that I think is representative of the whole. Not sure I will go to that extent though. Skotty 01:09, 22 June 2011 (UTC)
I'd definitely say that you still have non-negligible bugs / issues with your surfing. Looking at Barracuda and HawkOnFire again, compared to DrussGT we have 95.82 vs 99.83 and 97.91 vs 99.91. In other words, both are hitting you ~20x as much, totally unrelated to how you log/interpret stats (because they're HOT). Not to be a downer - XanderCat is coming along great and you appear to have a really robust code base. Or if you're burning out on 1v1, how about Melee? It's a much different animal. =) --Voidious 01:28, 22 June 2011 (UTC)
- It appears as though I'm on the right track with version 4.8. Just for you Voidious (grin), in addition to other changes, I configured it to maximize scores against head-on targeters, which raised the Barracuda and HawkOnFire scores to 98.98 and 98.76 respectively (2 battles each so far). To get the rest of the way to DrussGT levels, I will need to tweak my dive protection a little more; it still causes XanderCat to stall near a wall long enough to be hit every once and awhile. I may need to also tweak my "Ideal Position Drive" a bit more too, as it still drives too close to opponents occasionally when trying to reach an ideal position (the Ideal Position Drive drive runs at the start of each round before bullets start flying).
- Nice. =) For better or worse, the RoboRumble greatly rewards bots that can annihilate HOT and other simple targeters, so you might be surprised by how much of a ranking increase you can find by polishing that aspect of your surfing. It's not always the sexiest thing to work on, nor the most fun... But more importantly (to me), it's just a good way to verify that your surfing is working how it should. I can't find a good quote, but both Skilgannon and Axe have commented on the fact that if even a single HOT shot hits you, there's something wrong. --Voidious 17:51, 22 June 2011 (UTC)
- Very true. A wavesurfing bot should be able to dodge all *known* bullets perfectly, and HOT is only known bullets. Unless there is something funky like bullets fired from 20 pixels away, or a gun cooling time of 1 tick, all bullets *should* be avoidable.--Skilgannon 11:54, 23 June 2011 (UTC)
- Nice work, but just as a note, some might think me crazy, but I don't think *any* explicit dive protection is necessary for this sort of thing really. My surfing bots RougeDC and Midboss (same movement code), get 99.5% against HawkOnFire with no explicit dive protection whatsoever (and in certain past versions they did even better IIRC). The thing is, as I see it, dive protection is completely unnecessary if the surfing properly considers how movement changes botwidth. I much prefer it that way as it doesn't require tweaking/tuning to get right. Just my 2 cents on dive protection. --Rednaxela 20:50, 22 June 2011 (UTC)
- Well, I'd still call it "dive protection". =) But yes, I agree that multiplying danger by bot width (or dividing by distance, which I think is still what I do) is about the most elegant solution. And I doubt anyone's calling you crazy. Do any top bots since Phoenix use special cases? I guess I'm not sure about GresSuffurd or WaveSerpent. --Voidious 21:14, 22 June 2011 (UTC)
- Oops, I guess I'm out of touch. Diamond still has special cases, despite taking this approach - it scales the danger more than linearly beyond a certain threshold, as Dookious did. Maybe I'll test removing that, just for the sake of argument. =) I think it will lose points, though. Sure, for one bullet, the danger scales linearly with bot width. But that bot width affects future waves too. I suppose whether this is "explicit dive protection" would be up for debate. --Voidious 21:24, 22 June 2011 (UTC)
- Hmm...considering my own robot width when surfing...why didn't I think of that before? Guess what new feature will be in version 5.0? :-D Skotty 22:44, 22 June 2011 (UTC)
- Rather than multiplying danger by bot width, I prefer integrating over the affected bins, since many bins can be covered at close range... ;) --Rednaxela 22:49, 22 June 2011 (UTC)
- GresSuffurd has 2 lines of code handling both distancing and dive protection. This code hasn't been changed for years. The dive protection just handles the angle, not the danger. My latest effort was to use the summed danger of all covered bins instead of the danger of one bin to decide which direction to go(forward, stop, backward), but this approach let me fall out of the top-10 ;-) Sometimes a simple, proven, not optimal solution works better than a theoretical optimal solution. I do like the idea of letting danger instead of angle decide when to change direction though, and I will continue in this path with the next versions. Welcome to the dark caves of Robocode. --GrubbmGait 23:25, 22 June 2011 (UTC)
- If it's ever pitch black, watch out for GrubbmGait's pet Grue ;) --Rednaxela 00:21, 23 June 2011 (UTC)
- I think the reason these approximations often work better is that we're using a discrete system, and often the optimal assumes continuous. I think the other reason is that the optimal system often gets horrendously complex and bugs creep in, making the simple system actually more accurate. But these are just thoughts =) --Skilgannon 11:54, 23 June 2011 (UTC)
- Well, in this specific case, I would say the "optimal system" doesn't get more complex. I would argue integrating over botwidth is less complex, because:
- It also implicitly does the most important part of what many people use bin smoothing for
- There aren't really any parameters to need to tune
- To be clear, a very very very tiny amount of bin smoothing is still useful, to cause it to get as far as possible from danger, but the integrating over botwidth really does the important part of the smoothing. Actually, I suspect that if people get lower scores with integrating over bins, it's because it overlaps with their existing smoothing which has become far too strong.
- Basically, sometimes the "optimal system" may actually be less complex. It can reduce how many tunable parameters are needed, and also replace multiple system components necessary to fill a purpose. --Rednaxela 13:37, 23 June 2011 (UTC)
- Well, in this specific case, I would say the "optimal system" doesn't get more complex. I would argue integrating over botwidth is less complex, because:
- I also think we tune around a lot of arbitrary stuff in our bots. I remember PEZ and I often lamented how something we'd set intuitively, and "couldn't possibly be optimally tuned!", resisted all attempts to tune it. I imagine that's sometimes the case when an existing simple/approximate approach performs better than the "new hotness totally scientifically accurate" approach. Dark caves indeed. =) --Voidious 14:48, 23 June 2011 (UTC)
- For the record, I don't use binsmoothing, as I don't see the purpose of it. If a safe spot is near danger or far away from danger does not matter, it is still a safe spot. --GrubbmGait 19:16, 23 June 2011 (UTC)
- Oops, I guess I'm out of touch. Diamond still has special cases, despite taking this approach - it scales the danger more than linearly beyond a certain threshold, as Dookious did. Maybe I'll test removing that, just for the sake of argument. =) I think it will lose points, though. Sure, for one bullet, the danger scales linearly with bot width. But that bot width affects future waves too. I suppose whether this is "explicit dive protection" would be up for debate. --Voidious 21:24, 22 June 2011 (UTC)
Case Analysis
Just out of curiousity, does anyone have any insight as to why deo.FlowerBot 1.0 drives so predictably against gh.GresSuffurd? I can't figure it out. FlowerBot just drives around in a big circle when fighting GresSuffurd, while seeming far less predictable against XanderCat 4.8. Maybe it's a distance thing? Looking a little closer, I see that a lot of top robots are only getting about 70% against FlowerBot, so perhaps it's just a lucky tuning on the GresSuffurd matchup (or unlucky, in the case of FlowerBot).
I'm hunting around to find cases where XanderCat performs poorly in cases where top robots perform very well. So far I haven't found a case I can learn anything from. I'll keep looking...
Flowerbot has a bug. This bot is derived from the (original) BasicGFSurfer which had a flaw when bullets had a power of x.x5 It could not match the bullet to a wave due to a bug in the rounding, therefor it did not 'count' the hit as a hit in its surfing. Just try out and always fire 1.95 power bullets at it, you will obliterate it. There are still some more bots using this codebase, so this 'bug-exloiting' could gain some points for you. --GrubbmGait 19:25, 23 June 2011 (UTC)
- Yep. That's it. Skotty 19:35, 23 June 2011 (UTC)
Which Waves to Surf
Anyone tried surfing all enemy waves at the same time? XanderCat currently surfs the next wave to hit, but I've been thinking about trying to surf all enemy waves simultaneously. Not sure if it would be worth trying or not.
Yep, many modern bots do. I surf two waves and weight the dangers accordingly. Doing more or all waves (would be just a variable change) would have almost no effect on behavior, because 3rd wave would be weighted so low, but cost a lot of CPU. --Voidious 19:45, 23 June 2011 (UTC)
In addition to what Voidious says, I'd like to note that going beyond two waves without eating boatloads of CPU could perhaps be done if one tries to be creative. One option is doing something like two and a half waves. What I mean by "half" is for the third wave, taking an approximate measure such as "If waves 1 and 2 are reacted to in this way, what is the lowest danger left for wave 3 that is approximately possibly reachable?". That approach leaves the branching factor of the surfing equal to 2-wave, but allows the 3rd wave to break ties in a meaningful way. Now... I haven't actually tried this, but just a thought about how to go beyond 2 without eating too much cpu. It might help in cases where the reaction to the first two waves would normally leave it particularly trapped... --Rednaxela 21:16, 23 June 2011 (UTC)
- I'm trying out surfing 2 waves at once for version 5.0, but I'm not sure how well it will work. I'm currently weighting the danger of the closer wave at 80%, and the 2nd wave (if there is one) at 20%. This is more a gut feeling for now. I may have to change it later. On a related note, version 5.0 pays more attention to robot width, such as determining when enemy bullet waves hit and when they are fully passed, but I was torn as to when to stop surfing the closest wave. Do I continue to surf it until it is fully passed, or do I stop surfing it right when it hits to try to get an earlier start on the next wave? For now, I'm doing the latter. Skotty 13:15, 24 June 2011 (UTC)
- About weighting between the waves, I believe one popular approach is weighting by (WaveDamage+EnergyGainOpponantWouldGet)/(distanceWaveHasLeftToTravel/WaveSpeed). This approach is nice because it gives a reasonable weighting of waves in "ChaseBullet" scenarios.
- As far when to stop surfing a wave... what I personally do, is surf the wave until it has fully passed, BUT I reduce the danger to 0 for the exact range of angles that would have already hit me (this is all using Precise Intersection to determine what range of angles would hit for each tick). This means that a wave that has almost completely passed me, will still be getting surfed, but care about those few angles that could still possibly hit (meaning, very low weight often). --Rednaxela 16:47, 24 June 2011 (UTC)
- Yeah, (damage / time to impact) is good, maybe squared. I can't remember if XanderCat is reconsidering things each tick (ie, True Surfing) or not, where that formula makes sense. While Rednaxela's setup is by far the sexiest, in a less rocket sciencey system (such as Komarious), I definitely favor surfing the next wave sooner - like once the bullet's effective position* has passed my center. (*Dark caves note: in Robocode physics, a bullet will advance and check for collisions before a bot moves. So for surfing, I add an extra bulletVelocity in cases like this.) --Voidious 17:53, 24 June 2011 (UTC)
- Originally, XanderCat was reconsidering things each tick, but I was running into what I referred to as "flip flopper" problems, where XanderCat would keep changing it's mind, and it seemed to be hurting performance. So I switched it to only decide where to go when a new bullet wave enters or leaves the picture (plus it processes less that way). However, I could see reconsidering every tick as being superior with the kinks worked out, and the "go to" style surfing has problems with dive protection. I therefore just modified my drive again to make the frequency of surfing configurable -- a hybrid approach between "go to" surfing and true surfing -- where I can set the max time to elapse before a reconsideration is performed; if the waves in play haven't changed before the time limit elapses, a reconsideration is executed. This becomes true surfing when you drop the time limit to 1. Not sure what value I will use for 5.1+ yet. Skotty 19:59, 24 June 2011 (UTC)
Rolling Average
I notice you say you are using a very high rolling average in both movement and gun. I have found in DrussGT that the gun should have a very high rolling average, but the movement a very low one to deal with bots that have adaptive targeting. By low I mean less than 5 on very coarsly segmented buffers, and less than 1 on finely segmented buffers. But I suggest you experiment with your own data and figure out what works best for you =) --Skilgannon 10:35, 27 June 2011 (UTC)
#1 Against PolishedRuby
I just checked for fun, and found that XanderCat currently holds the #1 score against PolishedRuby! Only 2 battles in the rumble, and only best by a slim margin, so XanderCat could slip down. But for the moment, I would like to claim my virtual gold medal against mirror bots. :-D —Preceding unsigned comment added by Skotty (talk • contribs)
Well, seems you certainly have a good anti-mirror system in place. I've never gotten around to building one of those... --Rednaxela 06:18, 1 July 2011 (UTC)
Fixing My Wave Surfing Rolling Depth
I think it is time for me to go back and really think about how I am processing segments to get a low rolling depth working properly on XanderCat. Let me start by giving a quick explanation of how I store my data, as it may be a bit different than what most robots do.
First off, I currently record two types of information. Hits and visits. Hits are recorded in a factor array using bin smoothing similar to what BasicGFSurfer does, and visits is just an incremented integer that says I was at a particular segment combination for a bullet wave, which I do for all bullet waves.
I store all of my wave surfing hit data in a 2-dimension array. The first dimension is the segment, the second dimension is the factors/bins. I can use any number of different segmenters. How this works is that I index all segmenters into the single segment array. So lets say I have segmenter A with 4 segments, and segmenter B with 3 segments, and 87 bins. My hit data array would then be a double[12][87] (3*4=12 segment combinations, 87 bins).
I store all of my wave surfing visit data in a 1-dimension array of int. Following in the former example, it would be an int[12] array. At present, this is used to balance the arrays when picking the best one (by dividing by total visits) and to decide whether or not I will consider using a particular segment combination. (e.g., I can say not to use a particular segment combo until it has seen at least X number of visits).
When I want to consider a particular segment combination to use for surfing any particular wave, I pull back all the indexes that match that segment combination and add the bin arrays for those indexes into a single combined array.
When I added rolling depth support, I was only thinking of rolling off hits. I created a List<List<Parms>> for this, where Parms was just a little class that holded the necessary information to roll back a previously added hit. The outer list index matched the segment index, while the inner list stored data for X number of hits. Once the list reached the preset rolling depth value, for every new hit it would remove the oldest hit from the list and roll it back. So, for example, lets say I get hit, and the combined segment index is 5, factor 23. This would get added to the hit data array (lets call this hitArray) centered at hitArray[5][23]. The hit would also get recorded in the rolling depth list (lets call this rollData) at rollData.get(5).add(new HitParms(...)). If the roll depth had been exceeded, it will then remove the oldest hit data in the list (rollData.get(5).remove(0)) and roll the old hit off the hitArray (same as adding a new hit, only it uses the saved data and applies a negative hit weight to remove the old hit).
To complicate things a tad further, I also add what I call a base load to whatever array is to be used for the current surf wave (this base load doesn't actually get added to the hitArray, it is added to a temporary array used for surfing the current wave). This base load is just the equivalent of a single head-on hit. It gets lost in the background when there is a lot of hit data, but is crucial in the beginning to avoid getting hit by head-on targeting.
And finally, I also store a combined no-segment array seperately, which I rely on early in the match when the segment combinations do not have a visit count over a certain threshold. I could obtain this by adding all segment arrays, but this seemed excessive, so I just store it in a separate array.
Given all this, I'm left wondering a few things. One, what do the rest of you really mean when you talk about having a rolling depth of 1 or 2. Are we talking rolling for every visit, every hit, or something else? Two, how should I handle avoiding head-on early in the battle when there is no data to rely upon without it messing up trying to use a low rolling depth (and will my current base load approach suffice for this)? Three, as I currently have it implemented, I can only roll hit data for all segments combined. I might could manually roll on the fly in the temporary array used for surfing, but I need to figure out what the rest of you are really talking about when you refer to rolling depth before I try such a thing.
—Preceding unsigned comment added by Skotty (talk • contribs)
Well, the usual "rolling average" method used in most targeting is far far simpler than what you describe. Usually exponential moving average is used. Instead of decrementing old hits, you just decay the weighting of old data. In a system like you describe with "hits" and "visits" kept separate, the exponential rolling average strategy would be, when you get a hit in a segment:
- First, multiply all values in "hits" and "visits" by a constant between 0.0 and 1.0.
- Then add your new hit and new visit, but multiply each by 1 minus the constant.
For an example, if you choose a constant of 0.5, then it means that with there is a hit in the segment, the old data will be worth half as much as before. Also, some bots do it slightly differently so the decay is constant, rather than only occurring when a segment is hit, though that takes a little more work to do efficiently.
The method you describe should work too, if you decrement both visits and hits when decrementing old hits I believe. I'm pretty sure decrementing both would be necessary to keep the values sane. Personally, I don't consider it worth the complexity, but diverse techniques is always interesting. :)
About the "base load", I'm pretty sure most bots do either of the following two things:
- Initialize the data to contain the "base load" (which means that in an exponential moving average system, it'll decay away to near-nothing pretty fast)
- or, make the "base load" a special case that only applies when there are no hits in the segment.
Hope that helps. --Rednaxela 23:56, 6 July 2011 (UTC)
Ok, a few things to tackle here. =)
- What most VCS / GF bots do is for each bin, the danger value is a number between 0 and 1. When data is logged for a segment, the value for each bin in that segment becomes
((rolling depth * old value) + new value) / (rolling depth + 1). The "new value" would be 1 for the hitting bin, some bin smoothed value < 1 for the rest. You might usemin(rolling depth, times his segment has been used)instead of rolling depth, a trick I learned from PEZ - ie, use the straight average if you don't have rolling depth's worth of data. A rolling average of 1 means all previous data is weighted exactly equal to the new data. There's no magical reason you need to use this style of rolling average, but it's pretty simple and elegant. Bots that don't use segments have to come up with different styles of data decay. - What you're referring to as a "visit" isn't what most of us are referring to. Generally, a visit is to a bin, not (just) a segment. A visit means "I was at a GuessFactor when the wave crossed me", as opposed to "I was at a GuessFactor when a bullet hit me". A visit is what a gun or a flattener uses to learn. What you're referring to as a "visit" is what you'd use in the min(rolling depth, x) example above, I think.
- About hard coding some HOT avoidance... Many bots use multiple buffers at once and sum the dangers from all buffers. In that case, you can just have one unsegmented array and load it with one shot at GF=0 instead of looping through every segment of all buffers. There are other benefits to summing multiple buffers of varying complexities, like having a balance between fast and deep learning (without having to figure out when to switch). In Komarious, I just add a tiny amount of danger smoothed from GF=0 after I poll my stats - mainly a Code Size-inspired trick, but not a bad approach. Diamond just uses a smoothed GF=0 danger when he has no data - this is only until the first time he's hit since he uses Dynamic Clustering.
Hope that helps! --Voidious 01:41, 7 July 2011 (UTC)
- And just a quick note to be clear, the "((rolling depth * old value) + new value) / (rolling depth + 1)" formula that Voidious cites is exactly mathematically equivalent to the method I was going on about above. It's just that the constant I used in my explanation is equal to "(rolling depth / (rolling depth + 1))". Two different ways of describing the exact same thing. Personally, I find what people sometimes term the "rolling depth" number less intuitive than the "what to multiply the old data by" constant, but it's really a matter of personal taste. I just through I'd point the equivalence out. :P --Rednaxela 02:07, 7 July 2011 (UTC)
What Voidious describes is exactly what I used to do - keep a whole bunch of buffers, where the bins represent the hit probability at that guessfactor, and when logging a new hit use a 1/((i-index)*(i-index) + 1) binsmoothing technique coupled with that rolling average formula he gave. There were 2 main problems: execution time (slow), and memory usage (high). I did what I could to get around this by hoisting the inverse of all the divisions outside of the loops and switching to floats, but that only helped so much. So, a while ago I changed my data-logging in DrussGT: instead of a whole bunch of arrays of smoothed hits - with around 100 bins - I instead now keep the guess factor of the last 2*rollingDepth + 1 hits. Each hit I weight less and less exponentially, by logging each hit into the bin it corresponds to (this is at wavesurfing time), and incrementing that bin with a value that gets progressively smaller. The factor I use for making the increment get smaller is roll = 1 - 1 / (sb.rollingDepth + 1), and each time I go through the loop I make the increment smaller by doing increment *= roll. By carefully choosing a starting value for increment I was able to make this system perform identically to the one that used the rolling average formula above while using a fraction of the CPU to log hits and a fraction of the memory to store them. Once all the hits are logged into their bin, I take this array of unsmoothed hits and smooth them. This has the huge advantage of taking any duplication of hits and essentially merging them again, speeding up the process further. Bins that don't have hits in them don't need to be smoothed, and in practice there are quite a lot of bins that are empty. Data logging has been sped up because instead of smoothing data into hundreds of buffers, each with a hundred bins, instead I just shift the hits over by one in these hundreds of buffers and add the new hit to the beginning. There are a few other tricks that I used to speed up the whole process, like only allocating the array for the hits once that segment has been hit and pre-calculating the indexes for all the buffers I need to access. But choosing this system has essentially eliminated all the skipped turns DrussGT used to experience, while still keeping all of my hundreds of buffers and all of my original tuning intact. --Skilgannon 09:23, 7 July 2011 (UTC)
- That's an interesting approach. It seems to me though, that once you're storing a list of hits, why not forgo bins entirely? It seems like it would be simpler and have essentially the same result. Maybe I'm wrong, but I'd think performance could also be improved further, with a method that instead of adding many sets of bins, concatenates a list of the
2*rollingDepth + 1hits from each segment, along with the weighting for each list entry. Then instead of calculating the value for a bunch of guessfactor bins, take advantage of knowing the integral of the smoothing function to do a fast and precise calculation of where the peak would be. Just a little thought. --Rednaxela 12:37, 7 July 2011 (UTC) - I've toyed with the idea of using some sort of DC system as a replacement, but the lack of rolling data makes me very hesitant. Also, it's not enough just having one peak (maybe you were thinking of targeting?): I need the danger at every point on the wave. I could use the raw data at each point I need to check, which would be slow, or I can take a whole bunch of evenly spaced samples, which is basically bins, which is what I am doing. My explanation was a bit complex I think. Perhaps a simpler explanation would be: when logging a hit, instead of smoothing the hit into a buffer, put it into a que (of which many exist, at their own 'location' just like a segmented VCS system) and delete the oldest entry in the que. When the time comes to stick the hits into a wave, go through the que and increment the bin in your 'wavebuffer' that corresponds with the GF of each hit in each que. Make sure that the older items in the ques are weighted exponentially lower. When you've put all the hits into that buffer, use a smoothing algorithm to, essentially, 'fill in the blank areas'. That's basically it, the rest is just implementation details.--Skilgannon 13:42, 7 July 2011 (UTC)
- By forgoing bins I never meant using DC. I mean segmented queues of hits like you have, but use non-bin methods to sum the data and find the peak. When not using bins for storage, I kind of feel it's a silly/wasteful to use bins for analysis of the stored data. As a note, I think DrussGT's movement may be the first actual implementation that fits the segmented log-based guessfactor category. See this chart I made a while back:
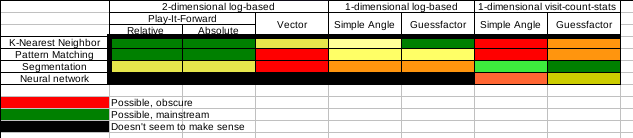
- --Rednaxela 14:01, 7 July 2011 (UTC)
- I think WaveSerpent might fit that too. (Maybe just WaveSerpent 1.x.) And, even further off-topic, I think ScruchiPu and/or TheBrainPi might belong in one of those black NN slots - for some reason I thought I recalled them being fed the tick by tick movements, not the firing angle / GF. --Voidious 15:59, 7 July 2011 (UTC)
- I think ScruchiPu and/or TheBrainPi are off this chart entirely. IIRC they are fed by tick by tick movements yeah, but that's neither log-based or visit-count-stat based, so it wouldn't fit in the black slots. It would go in it's own column. As subtype of "play-it-forward" but not a subtype of "2-dimensional log-based". --Rednaxela 16:32, 7 July 2011 (UTC)
- I think WaveSerpent might fit that too. (Maybe just WaveSerpent 1.x.) And, even further off-topic, I think ScruchiPu and/or TheBrainPi might belong in one of those black NN slots - for some reason I thought I recalled them being fed the tick by tick movements, not the firing angle / GF. --Voidious 15:59, 7 July 2011 (UTC)
- Off-topic, but... Decaying surf data in a DC system is kinda interesting. Designing a system for it in Diamond really made me appreciate VCS / rolling average. =) Instead of weighting things by age, I sort my "cluster" inverse-chronologically and weight each hit according to its sort position. I actually tried hard to figure out how to emulate a rolling average of 0.7 - the most recent data is weighted about 60/40 to the rest of the data, 2nd most recent is 60/40 to the rest of the rest, etc. That got me thinking about the golden mean, like in this image. I weight the most recent scan 1, and the rest by (1 / (base ^ sort position)), with a base of golden mean = ~1.618. So it's 1, .38, .24, .15. I figured the golden mean was cool and magical and this modeled rolling average = 0.7 pretty well, so I stuck with it. =P The first one basically gets a sort position of 0 instead of 1.
- Come to think of it, I really could model it to just weight it exactly how a rolling average 0.7 would in a segment. Maybe I'll try that. --Voidious 14:34, 7 July 2011 (UTC)
- /me waits for Rednaxela to come up with the real formula he should use to model the weights like the relative areas of the golden mean rectangles. =) --Voidious 14:43, 7 July 2011 (UTC)
- Yes, duh, I should square the golden mean since it's the ratio of the length of the sides, while the area is that length squared. And not special case sort position 1. I'm kind of excited to have something stupid like this to tinker with... =) --Voidious 14:49, 7 July 2011 (UTC)

{kind=link}
Might have to get back into things
I don't want to have yet another person pass my highest robots ranking, and XanderCat is getting pretty close. I might have to get things in gear and start robocoding again. But considering it has been in remission for a year, not sure if I want my addiction to relapse. ;) — Chase-san 00:46, 12 July 2011 (UTC)
- Don't worry. I just released a new version that lowered it's rank. :-P However, I am using a brand new drive and factor array system that are somewhat in their infancy (I really haven't given them enough shakedown yet, and a few bits are incomplete), so I do expect to climb back up into the top 50 eventually. I was at #49 at version 5.1.1. Still a long ways from the top, but just give me a little more time. :-) -- Skotty 00:57, 12 July 2011 (UTC)
- Yeah, you we're floating right below Seraphim, and thats why I say this. I have my pride, but her weak points are all the weak bots, her strong points are all the strong(er) robots. In perspective, she can defeats 3 (over 50% score only 2 if you use survival) robots in the top 10, but defeating robots in the top 10 does not get you high into the rankings. — Chase-san 01:22, 12 July 2011 (UTC)
Do you have any method of personal contact (E-mail, Messenger (AIM,Skype,Google Talk,Yahoo), IRC, Twitter), I wouldn't mind discussing things about robocode. — Chase-san 16:22, 12 July 2011 (UTC)
- I have an old AIM account, but I haven't been using it lately. If you are an active chat user, I could start firing it up on boot up again. Otherwise, I have an email account, but we need a secure way for me to send it to you that won't get picked up by spam bots. -- Skotty 03:01, 14 July 2011 (UTC)
Version 6.x Scores All Over The Map
Well...I'm officially confused. I've been seeing huge point swings against various opponents in the rumble even with minor changes, and it seems they are inconsistent with what I see at home. Though admittedly, I still need to put together a big stress test to get a larger performance sample. I'm still wondering if it may have something to do with missed turns, as I don't really know exactly what happens when a turn is missed (I can't find any docs that explain it thoroughly). Or maybe there are still exceptions happening. Or both, perhaps missed turns somehow causing exceptions. Hopefully I can figure it out because it is really driving me insane. Version 6.1.1 in the rumble actually lost a round to Barracuda, and that just doesn't happen. I'm going to try running v6.1.1 in the fast learning MC2K7 challenge tonight using RoboResearch, since that is already pretty much ready to go; not using any the Raiko stuff because I'm just doing it to see if any exceptions or other anomalies happen. Running 500 seasons, and will check on it in the morning. -- Skotty 06:07, 12 July 2011 (UTC)
- I think it is not help because roboresearch works with robocode version 1.6.4 and rr clients use robocode version 1.7.3 now and i notice, that there're some difference between them. If you want i can share little app, which may be called analogue of roboresearch with many restrictions, but it is designed to work with rc 1.7.3 --Jdev 08:14, 12 July 2011 (UTC)
- I have roboresearch working with 1.7.2.2 and have no problems with it. Don't see a reason why it shouldn't work with 1.7.3.0. --GrubbmGait 09:25, 12 July 2011 (UTC)
- As i remeber, RoboResearch requires modifications of robocode messages parser to work with last versions. But may be it was my unique troubles:) --Jdev 09:37, 12 July 2011 (UTC)
- You may be right, I did not get it from the source, but picked up a package of someone else (Voidious I think). --GrubbmGait 09:46, 12 July 2011 (UTC)
- As a note, this type of issue makes me wish that the roborumble client uploaded replay files when it uploaded results (Haha... that would take a lot of space). Actually... it would be nice even if it just uploaded skipped turn count along with the scores. --Rednaxela 12:22, 12 July 2011 (UTC)
- This morning it was up to 137 seasons of the MC2K7 fast learning challenge with no exceptions or anomalies. The skipped turns thing is still just a theory. Maybe I should intentionally make it run slower at home to try and cause some skipped turns to see what happens. On that same tangent, it is probably about time I worked on my robot's efficiency so that it isn't a potential issue. -- Skotty 12:45, 12 July 2011 (UTC)
- On the plus side, this whole thing has prompted me to finally build some nice CPU time profiling tools. Currently taking a closer look at how long various parts of the code take to execute. -- Skotty 13:44, 12 July 2011 (UTC)
- I'm still trying to figure out what the heck is going on. In version 6.1.2, the only change was to remove a debug print line that was in a bad place, causing part of the drive code to waste a couple of milliseconds when deciding where to go for a new wave. But check out the first battle result against nat.BlackHole 2.0gamma -- my survival went from 42.86 to 8.57 (difference from version 6.1.1 to version 6.1.2). I don't know if I am on the right track on trying to improve efficiency, but something is definitely still very wrong somewhere. I suppose I should try upgrading to the latest Robocode version and see what if any change that results in (I'm currently still using 1.7.2.2) -- Skotty 21:04, 12 July 2011 (UTC)
- Definitely use the rumble version to do ALL of your testing! It can make a big difference... You could be running into bugs in the old version or possibly in the new one.
- @Rednaxela, as usual you come up with interesting rumble ideas. I don't think storing a slug of data per bot would be unreasonable. Not every replay of course, but maybe a size-limited block of custom stats, exception reports, etc. The tricky part would be getting the rumble client to export it for the server, would probably require an API function. --Darkcanuck 21:40, 12 July 2011 (UTC)
New Theory on Performance Issues
I've been wondering if changing my robot to log exceptions to file is the reason for the performance anomalies. But I couldn't figure out how that would make sense until just now. Could it be that Robocode handles the following two situations differently (or perhaps, differently depending on Robocode version)?
- Robot run() method ends due to Exception
- Robot run() method ends normally
My new theory questions whether in some instances, a robot crashes but is reactivated to finish the remaining rounds, but in other instances it is out of commission for all remaining rounds. Before I added the code to log exceptions to disk, exceptions were not caught. Now they are caught, but they are caught outside of the main while() loop, causing the run method to exit without an exception. Without knowing how Robocode internally handles the robot threads, it is hard to say what effect this might have. -- Skotty 21:51, 12 July 2011 (UTC)
- It's been awhile, but I think that if the run() method exits, then your robot is done for the round! Doesn't robocode only call that once at the beginning of each round? You definitely want to catch and handle exceptions inside the loop so that your robot can keep playing, if possible. My bots use a while(true) loop inside run() and will never exit, except for an unhandled exception. --Darkcanuck 22:20, 12 July 2011 (UTC)
- The alternative is to do a try/catch inside the while() loop. And while this would help, it would also help mask Exceptions that happen. So on one hand, I want to handle them, but on the other, it's almost better for it to crash, burn, and throw a tantrum so I will actually see the problem and correct it, rather than having it erode my robots scores quietly. -- Skotty 22:33, 12 July 2011 (UTC)
Debugging XanderCat -- What Next?
I had at least one instance where XanderCat bugged out that ran on my own machine, but no exception report was produced (see XanderCat 6.1.4 vs MagicD3 0.41). This means it wasn't a runaway while loop. My next step is to start writing out short data files for every robot, every round. Then at the end of the battle, if everything went normally, the files will be deleted. In those files, I will write out the number of bullets I fired, and the number of bullets the opponent fired, my round hit ratio, and the absolute distance I traveled during the round. When I see a battle that went bonkers, here are the scenarios I will be looking for:
- Files present for some but not all rounds. This will indicate that the robot stopped operating completely.
- Files for all rounds present, but bullets I fired dropped dramatically or went to 0 at same point during the battle. This will indicate that my gun stopped firing.
- Files for all rounds present, but my hit ratio dropped dramatically or went to 0 at some point during the battle. This will indicate that my gun was firing but the aim went bonkers.
- Files for all rounds present, but the number of bullets opponent fired dropped dramatically or went to 0 at some point during the battle. This will indicate I stopped detecting the opponent's fired bullets.
- Files for all rounds present, but absolute distance travelled dropped dramatically or went to 0 at some point during the battle. This will indicate that my drive stopped working, and my robot just starting sitting still.
Anyone have any other suggestions as to what I might look for, or other ideas on how I might try to track this down? -- Skotty 13:32, 13 July 2011 (UTC)
What I've done is look at every single loop in my 4000+ lines of code, checking that each one has an exit clause, and if there isn't one hardcoding one in (using a countdown). I also put a try/catch around all my code so all my other code logs exceptions to disk. Otherwise, unless you have a security manager problem everything *should* be caught. In theory =) --Skilgannon 14:19, 13 July 2011 (UTC)
How about try the following: Set up a script that runs robocode repeatedly, with parameters that cause it to run XanderCat 6.1.4 vs MagicD3 0.41 AND save replay files, and have your script delete the replay file whenever the resulting score is above 50%? I've done command line scripting of battles before it's it's fairly trivial. I suggest this method because it should catch the problem in action regardless of the cause. --Rednaxela 14:34, 13 July 2011 (UTC)
- Switching to the most recent client for my testing was a good idea. Things are definitely different in version 1.7.3.0 than they were in 1.7.2.2. I think, for one, I have potentially fallen victim to a change in how Bullets are handled. My overall hit ratio in 1.7.3.0 keeps coming back 0, whereas it worked fine in 1.7.2.2. I have to look into it more, but I think it has to do with how I am handling the Bullets. I vaguely recall once seeing some Robocode issue related to Bullets, but I don't recall where at the moment. I'll have to dig into it more... -- Skotty 21:29, 13 July 2011 (UTC)
- Here it is: bullet.equals semantic has been change in 1.7.3.0 version - ID: 3312402. This is likely the root of all evil in my 6.x series of robots. I guess I can't trust on matching bullets by the actual Bullet objects. I will have to come up with some other way to keep track of them. After doing this, I bet all my other troubles will fade away. Note that the issue says it is fixed, but it doesn't really say in what version it is fixed (was it broken in 1.7.3.0, fixed in 1.7.3.0, then re-released as 1.7.3.0, or is it fixed in the source tree but we won't see it until 1.7.3.1 or whatever the next version is?). If it is supposed to be fixed in 1.7.3.0, then I would bet the equals() method was changed without also adding or updating the hashcode() method, ultimately breaking the hashcode() contract that states: "If two objects are equal according to the equals(Object) method, then calling the hashCode method on each of the two objects must produce the same integer result." I say this because I was using Bullet objects as keys in HashMaps. If hashcode() isn't right, this would cause a HashMap lookup to fail when equals() does not. -- Skotty 21:34, 13 July 2011 (UTC)
- What this bug means for XanderCat, is that all the gun hit ratios are broken. The gun used is selected by the hit ratio. I give bias so that XanderCat prefers the guess factor gun, so the guess factor gun is probably still getting selected most of the time, but at other times, it probably does crazy things like selecting the linear gun and only the linear gun for the entire duration of a battle. I don't know that for sure, but it's fairly likely given the problem. -- Skotty 22:10, 13 July 2011 (UTC)
- Ahhh that. That bug was reported against 1.7.3.0, and the fix is in the source tree and it will be in 1.7.3.1. As far as I understand, robocode used to give identical bullet objects, but at some point it had to give different objects due to architectural changes. The fix to 3312402 was implementing equals(). Oh, and hashcode() is also properly implemented, I checked (that was added 2 days after equals() was, both shortly after 1.7.3.0). --Rednaxela 22:09, 13 July 2011 (UTC)--Rednaxela 22:09, 13 July 2011 (UTC)
- Here it is: bullet.equals semantic has been change in 1.7.3.0 version - ID: 3312402. This is likely the root of all evil in my 6.x series of robots. I guess I can't trust on matching bullets by the actual Bullet objects. I will have to come up with some other way to keep track of them. After doing this, I bet all my other troubles will fade away. Note that the issue says it is fixed, but it doesn't really say in what version it is fixed (was it broken in 1.7.3.0, fixed in 1.7.3.0, then re-released as 1.7.3.0, or is it fixed in the source tree but we won't see it until 1.7.3.1 or whatever the next version is?). If it is supposed to be fixed in 1.7.3.0, then I would bet the equals() method was changed without also adding or updating the hashcode() method, ultimately breaking the hashcode() contract that states: "If two objects are equal according to the equals(Object) method, then calling the hashCode method on each of the two objects must produce the same integer result." I say this because I was using Bullet objects as keys in HashMaps. If hashcode() isn't right, this would cause a HashMap lookup to fail when equals() does not. -- Skotty 21:34, 13 July 2011 (UTC)
Empty Output Files
Anyone else ever have trouble with an output file being empty? I've had a lot of cases where I try to write something to a file in Robocode, where the file gets created, but it is empty and nothing gets written to it. Here is the end of my run() method (see below), that should write Exceptions to file. It usually works, but tonight I noticed I had an empty one. This was also happening with my diagnostic output files.
} catch (Exception e) {
File exceptionFile = getDataFile(getName().split(" ")[0] + "_Exception.txt");
log.error("Fatal exception occurred.");
log.error("Writing stack trace to " + exceptionFile.getAbsolutePath());
RobocodeFileWriter writer = null;
try {
writer = new RobocodeFileWriter(exceptionFile);
String s = e.getClass().getName() + ": " + e.getMessage() + "\n";
writer.write(s);
log.error(s);
for (StackTraceElement ste : e.getStackTrace()) {
s = ste.toString() + "\n";
writer.write(s);
log.error(s);
}
writer.close();
} catch (IOException ioe) {
if (writer != null) {
try {
writer.close();
} catch (Exception ce) { }
}
}
}
I'm not sure at the moment if the file gets created when the RobocodeFileWriter gets created, or after the first call to write. But either way, how would the file end up being empty? I did not call flush(), and maybe I should, but it really shouldn't make any difference as long as close() gets called. I am also calling log.error(String) in there, which writes to System.out, but I wouldn't think that would cause any problems. I had this same problem with my diagnostic output files...sometimes they would have data in them, other times the files would be there but empty. Thoughts? -- Skotty 04:51, 14 July 2011 (UTC)
- One would think it would, but it is better to remove it as a possible factor by flushing it manually. If that doesn't work... well. To be honest I don't work with robocode File IO much. — Chase-san 04:57, 14 July 2011 (UTC)
- In addition to that, there is at least one more bug I have to find, as shown by this battle: XanderCat 6.1.7 vs MoxieBot 1.0. MoxieBot got almost no bullet damage, but won half the rounds. Had to be an exception or something there. :-( -- Skotty 05:01, 14 July 2011 (UTC)
- UPDATE: No exception on MoxieBot; was just due to MoxieBot using very good bullet shielding. -- Skotty 15:39, 14 September 2011 (UTC)
- In addition to that, there is at least one more bug I have to find, as shown by this battle: XanderCat 6.1.7 vs MoxieBot 1.0. MoxieBot got almost no bullet damage, but won half the rounds. Had to be an exception or something there. :-( -- Skotty 05:01, 14 July 2011 (UTC)
- It may just be that the file operations are happening too slowly due to the large number of files in the folder. My diagnostics I had in originally created a file for every round of a battle that had anomalous results. I didn't expect battles against every single robot to have anomalous results, but they did, so there are thousands of tiny files in the folder. XanderCat 6.1.7 slowly cleans up the old files, but it will take a while before they are all gone. Maybe after the number of files is back down to a reasonable number, it will start working normally again. -- Skotty 05:28, 14 July 2011 (UTC)
New Factor Array Idea
I have a new idea for handling factor arrays that I will be trying out soon. I've already implemented it, but haven't put it to the test yet. The idea is to start off all factor arrays with a set amount of "weight" already evenly (or close to evenly) spread within the factors. This total amount of weight in the factor array never changes. Instead, when a hit is logged, the total "weight" added by the hit is removed evenly across all factors such that the total weight in the array does not change. The weight is simply redistributed.
I'm interested to see how well it works, but at the same time, I am not very hopeful. The redistribution will act much like "rolling" (or "array decay", as I like to call it), but will only occur on an array when hits are logged to it. -- Skotty 03:46, 12 August 2011 (UTC)
- This provided no improvement in practice, and it just added more complexity, so I ditched it. -- Skotty 15:38, 2 September 2011 (UTC)
Next Plans -- XanderCat 9.x -- September, 2011
I haven't uncovered any serious bugs in my robot, but I do have a plan for where to go next.
- First, and perhaps foremost, is re-assessing what segmentation is used. Over the next few weeks I will be doing a lot of RoboResearch on various segmentation combinations. Perhaps I will find that one or more of my existing segmenters is problematic, or buggy. Perhaps I will find that I just need to switch a few segmenters. Whatever the case, I think this holds a lot of potential for improvement.
- Second, and I have to verify this, but I do not think I am currently using information on bullet-hit-bullet events to add data points to my drive data. I drop the waves, but I think I overlooked using the information in my drive (if I know the opponents aim, I can add a data point even though I didn't actually get hit). How helpful will this be? Well, it should help the robot learn a little faster, and that could be good for a small boost.
- Third, I may look into utilizing bullet shadow. This may require a modification in how I process waves though. It could lead to another small overhaul of part of my framework.
It looks like you attained your top 40 goal. Congrats!--AW 15:01, 12 September 2011 (UTC)
- Woot! Thank you! -- Skotty 18:12, 12 September 2011 (UTC)
Using bullet-hit-bullets to add surfing data gave me quite a boost. I refactored some of my code so that instead of logging hits I log bullets (robocode Bullet objects) and it made the whole thing take an extra 6 lines of code or so =) I even do this in my surfing minibot. --Skilgannon 06:01, 13 September 2011 (UTC)
- Take a peek at my code? Some of my drive code is still a little messy (due to playing with different ideas), but you may have noticed in my class AbstractFactorArrayProcessor, I don't do anything in the oppWaveHitBullet and myWaveHitBullet methods. I also need to start passing the actual Bullet to those methods. Regardless, it's good advice. I will put that at the top of my TODO list. -- Skotty 12:44, 13 September 2011 (UTC)
- I didn't actually, but you know what they say about great minds ;-) Seriously, this had a noticeable impact on my surfing abilities even a minibot level, so if you want some guaranteed score get onto it ASAP. --Skilgannon 13:25, 13 September 2011 (UTC)
- Just wanted to mention that a bulletHitBullet event has getX() and getY() metohds. Before I knew that, I thought adding this would be really hard, but you can basically use the same code that you use when the enemy hits you. (Remember not to log it in both the oppWaveHitBullet and the myWaveHitBullet methods)--AW 13:56, 13 September 2011 (UTC)
- I made this change. However, against my test bed of robots, the score increase was only 0.2 APS. This will probably translate to about 0.1 APS in the Rumble, based on how my test bed has related to it in the past. Could even be less, as I currently only run 10 seasons for my test bed. I'm pretty sure I implemented it correctly as it wasn't that complicated of a change. Would you have expected a more signficant change than that? -- Skotty 15:35, 14 September 2011 (UTC)
- Sorry I'm late, but congrats from me too. =) I think that would be about top 10 at the time when I joined. :-P As to your question, I would expect more of a gain than that, but maybe you'll see that in the rumble. Everything you learn from a BulletHitBullet is something you wouldn't have learned until you actually got hit by a bullet. I remember being surprised by how much it gained when I added this to Komarious, but unfortunately it was right before the switchover to Darkcanuck's server and the score diff is lost forever... --Voidious 16:01, 14 September 2011 (UTC)
- Guess I should go back over it with a fine toothed comb and make sure I didn't make any mistakes. I'd hate to miss out on a big jump in score. :-) -- Skotty 16:28, 14 September 2011 (UTC)
- Sorry I'm late, but congrats from me too. =) I think that would be about top 10 at the time when I joined. :-P As to your question, I would expect more of a gain than that, but maybe you'll see that in the rumble. Everything you learn from a BulletHitBullet is something you wouldn't have learned until you actually got hit by a bullet. I remember being surprised by how much it gained when I added this to Komarious, but unfortunately it was right before the switchover to Darkcanuck's server and the score diff is lost forever... --Voidious 16:01, 14 September 2011 (UTC)
New Segmenter
I may have struck a little gold in some testing tonight. I decided to try out a new segmenter, and initial results against my current test bed are surprisingly good. Maybe a big part of my problem is not bugs I can't find, but things like not having the right segmenters yet. The new segmenter will see action in version 9.0 of XanderCat, which I expect to have done on or before this weekend. -- Skotty 01:37, 9 September 2011 (UTC)
Version 9.5 - Interesting Results
Version 9.5 included switching to using my data from time-2 for opponent waves, and a first run of surfing multiple waves. The results were interesting.
First off, something weird happened against YersiniaPestis 3.0 on darkcanuck's server. I highly doubt the 2 scores of 90 against it are legit. That would be vudu magic.
Scores in general are more varied than in previous versions, but that could just be because there are not enough battles yet. So far scores against Barracuda and HawkOnFire are up, which can be credited to the second wave surfing.
I'm seeing a few skipped turns for the first time ever. That is due to the extra processing required to do the second wave processing. I need to go back and see if I can make it more efficient now. I also haven't fine tuned the second wave processing, so there could be some more points to pick up there.
I had played with rolling drive data with some mixed results before releasing this version. However, for this version, I decided to continue not rolling any data. I need to do more analysis on this before I try to change it (or even if). —Preceding unsigned comment added by Skotty (talk • contribs)
- One cool speed optimization for multi-wave surfing, which I think Krabb taught me: After calculating the danger on the first wave, don't bother calculating second wave dangers for that movement option if the first wave danger is already higher than the best danger you've calculated so far. (Sounds obvious now... =)) If you also calculate the safest movement option from last tick first, that helps even more. Overall it's a really nice speed increase with no change to behavior. --Voidious 15:11, 20 September 2011 (UTC)
- Yep, this optimization is the only thing that stops DrussGT from falling over flat. I first do all my first-wave predictions, then sort them in ascending danger. As I go through, once I get a first wave danger that is higher than my lowest first+second wave danger I know I can immediately quit because the dangers will only be higher after that. Brilliant solution. Another thought is that you might want to play with the weighting of the different waves - I found that inverse time-till-hit worked quite well. Waves that are closer are higher priority, and waves that are further away can be dealt with, for the most part, later. --Skilgannon 06:02, 22 September 2011 (UTC)
- Just on a sidenote: dangers don't change if there is no new info, so you only have to recalculate them if new info is present (bullet hit, bullet hit bullet). You still have to determine the complete danger for f.e. multiwave, but that is just peanuts. But maybe I am just talking VCS and is DC a complete other situation. --GrubbmGait 08:56, 22 September 2011 (UTC)
- Nah, it's the same for other systems such as "DC" too. --Rednaxela 13:04, 22 September 2011 (UTC)
- Except that in my true surfing (and I suspect many others), waves are weighted by time to impact, which changes tick by tick. This is the big thing I'd grapple with if/when I try some go-to surfing. —Preceding unsigned comment added by Voidious (talk • contribs)
- Sorry, just to elaborate: You could, of course, cache the danger before applying time to impact. And, more conservatively, you could cache the precisely predicted locations that should be identical for whichever predicted path you moved along last tick. Historically, I've not done this because it seems ugly and error-prone, but I'm almost inclined now to give it a shot. --Voidious 14:41, 22 September 2011 (UTC)
- Well, to start with, I haven't done correct multi-wave surfing yet (still re-writing my movement) but I don't see why weighting waves by inverse time to hit could help except that it is more probable that your data on the waves that will hit later will be updated. Is there any other reason to weight the waves by time to hit if you are calculating all movement options for the second (or third etc.) wave?--AW 15:07, 22 September 2011 (UTC)
- The short answer is: I didn't think I needed to either when I first did my branching multi-wave surfing algorithm, but it performed better if I did. =) (I knew other bots weighted by time to impact.) But I can rationalize it. With True Surfing, each tick you're considering 2-3 movement options. When the two waves are 15 and 30 ticks away, it's unlikely that any of the 2-3 spots you're considering are where you'll finally end up - it's more of a "broad strokes" calculation to determine a direction, so considering both waves is important. As the first wave gets closer, it's more important to really decide which spot exactly on that wave you think is safest, and the second wave options for each of those spots are getting more and more similar anyway. When the nearest wave is only 3 ticks away, there is a ton of overlap on the second wave options. It's kind of silly to put a lot of weight on which 2-3 points come up for each of the second wave options - those same points might be reachable from any of your first wave options, meaning it's just random noise which ones happened to come up for each first wave option. --Voidious 15:18, 22 September 2011 (UTC)
- I can definitely see how it should help with that, but if your robot predicts every possible movement option, I would think that there is a better way to do this. To rephrase my idea, suppose you could see the enemy's bullets, then the safest movement option (or rather a safe movement option) would be where neither bullet would hit you. Now suppose the enemy fires waves with bullets of different powers at different angles and you could see these, the safest movement option would be the one that minimizes your damage. The assumption I am making is that if instead of multiple bullets at each angle you had an estimate of the probability he would shoot using any given angle this would still be the best possible movement option. I am pretty sure this is correct, but I need rednaxela to verify it. If this is the case, then the weighting of each wave should be based on the probability that your best estimate will change before the wave breaks.--AW 16:28, 22 September 2011 (UTC)
- I'm somewhat intrigued by what Skilgannon said. Bare in mind that XanderCat uses GoTo surfing. Right now, I start by picking a first and second choice on the first wave, then use those two points as starting points for the second wave. But I may have been more in a true surfing mindset when I set it up that way. Using Skilgannon's approach, I could consider a range of possibilities for the first wave, not just a first and second choice, ordered by danger and short-circuting second wave checks in the manner Skilgannon described. So long as I can keep it reasonably efficient, I'm willing to bet that will give me another performance boost. I'll have to experiment more with wave weighting as well. Right now, I weight the first and second waves equally regardless of their proximity, for much the same reasons as AW is speaking of, but I haven't really put a lot of thought into it yet. -- Skotty 20:23, 22 September 2011 (UTC)
- You really should consider the closest wave more dangerous, just like dodgeball. The first wave limits your range to move the most, while the second wave decides which direction to move if for the first wave the danger is almost the same on the whole range. Normally there is time to reach a reasonably safe spot when the second wave becomes the first wave, although it is true that the safest spot for the second wave can be out of reach because you had to dodge the first wave. Hmm, maybe I have to rethink my second-wave implementation, because currently it is just a first-wave calculation with a lower weighting. --GrubbmGait 21:18, 22 September 2011 (UTC)
- Another reason to weight the first wave higher is that it is certain that this is the information you will be surfing. When surfing the second wave as the new first wave (once the current first wave has passed) there will be a new second wave, so the stats will have changed. Because of this, although the second wave can certainly help with choosing where safe locations will be, there is a high probability that once you factor in the wave after it as well it will change quite a bit. Because of this, weighting the closer waves higher seems to help, or at least this is my thinking. Another thing that changes is distances - if the enemy robot moves right next to where your third wave safe points will be, that area is no longer as safe so the data you were surfing earlier is now useless.--Skilgannon 06:43, 23 September 2011 (UTC)
Melee Rumble
I finally started working on some components for the melee rumble. I was thinking I would add them as another scenario to XanderCat, but I'm not sure if I really want to add that extra bloat to it or not. I could release an entirely different robot for melee-only (same framework though). But I like the idea of adding it to XanderCat to expand on it's presence and multi-mode nature.
I finished a melee radar, and about half finished a melee gun. Still need to write a drive. My framework needed some minor adjustments to fully support melee combat, but nothing significant. It shouldn't be too long before I can put them to use.
Best Bot Page Candidate
I just wanted to say that I find your extensive information on how your built your bot and why to be an invaluable well of inspiration. If we had a reward for best bot page I would but XanderCat's up among the top. It might be the #1 even, I haven't looked around too much lately. Thanks! -- PEZ 09:40, 4 November 2011 (UTC)
- Thank you! I still feel it needs further improvement, but I have indeed put a lot of work into it. Parts of it are still in a state of semi-experimentation, and I do change things periodically. I try to keep the pages on the wiki up-to-date, but feel free to contact me if you have questions about some of the things that I have done, or if you are wondering if something I have written is still accurate, or if you just want to chat about design options or ideas. And welcome back! I'm happy to see you back in action! -- Skotty 01:23, 5 November 2011 (UTC)
KD-Tree
Are you using Red's 3rd generation tree found here. It uses parts from the dataStructures directory, so keep that in mind. — Chase-san 21:41, 1 December 2011 (UTC)
- [View source↑]
- [History↑]
Contents
| Thread title | Replies | Last modified |
|---|---|---|
| Wacky Version Problems with RoboJogger/RoboRunner | 1 | 03:29, 3 April 2017 |
| New Garbage Collection Mitigation Strategy | 4 | 14:16, 26 October 2013 |
| Garbage Collection and Skipped Turns | 23 | 19:54, 24 October 2013 |
| Shielding Success Rates Mystery | 27 | 23:49, 27 February 2013 |
| When to shield | 1 | 15:43, 25 February 2013 |
| Initialization Code Runtime Reduction Effort | 19 | 02:30, 18 February 2013 |
| Fast Math | 3 | 05:18, 17 February 2013 |
| Version 12.1 | 28 | 20:44, 15 February 2013 |
| Code size records | 6 | 10:42, 9 February 2013 |
| Anyone Have a Huge Challenge File? | 13 | 18:21, 4 February 2013 |
| Moving up past 85 APS -- Not Easy | 8 | 04:59, 31 January 2013 |
| Lesson in Parasitic Losses | 3 | 05:40, 20 December 2012 |
| Doh! Lucky win? | 0 | 18:15, 19 December 2012 |
| PrairieWolf | 4 | 05:29, 18 December 2012 |
| 11.6 | 1 | 19:50, 24 November 2012 |
| Another challenger for PL Crown? | 0 | 11:16, 2 December 2011 |
| Version 11.1 Issue | 2 | 15:59, 27 November 2011 |
| Twitter issue | 2 | 00:52, 27 November 2011 |
| Top 10 | 7 | 07:06, 23 November 2011 |
| Bullet Shadows Fixed, 1668 PL (for the moment) | 2 | 16:33, 9 November 2011 |
First page |
Previous page |
Next page |
Last page |
Forgot how slow this can go. :-/ I've been trying all day to record some new statistics using the Robocode means for saving file to disk, but I'm getting really bizarre version issues. I've been updating my robot version with each change -- 12.8.1, then 12.8.2, then 12.8.3. Each time I clear robot cache, package the new version, clear the old stats file that was saved from the prior version (as in, physically delete it, so I know the old stats are gone), and then run a new challenge with the new version. However, I keep getting garbage from older versions coming out in the results. Sometimes mixed, like it's randomly running different versions.
I've started trying to record the version information to the stats file each battle. I keep seeing this in the saved information:
Old: xander.cat.XanderCat 12.8.1*; New: xander.cat.XanderCat 12.8.7.
What that means, is it thinks the last battle was run with 12.8.1*, even though the entire challenge was run with 12.8.7. And that may actually be sort of true, because I'm getting some info in the stats file that I removed around version 12.8.4 but it shows up again, like it ran an older version for one or more of the prior battles.
At the moment, I'm totally confused by it. I'm not even sure how to debug it further at the moment.
As sometimes happen, writing about it made me figure it out. What was happening, that I didn't realize, was that the newer version of Robocode has an option to include the data files in the packaged robot, which is checked by default. So it was packaging data from an old version of XanderCat that I had run from Eclipse, which was totally screwing with my robot frameworks attempt to manage the robot data.
If you want to save any persistent data to the data files, make sure you uncheck the option to include data when packaging the robot!
Can't believe how much time I wasted figuring that out today.
I spent some time working on a system to pool frequently used objects in an attempt to mitigate the first round garbage collection problem my robot suffers from. My first attempt had some merit, but the changes involved are a lot more significant than I would like. I'm just not happy with it.
Recently, however, I came up with another idea that may be much simpler and effective. However, I still need to test out the idea. Instead of managing object pools, what if I just dump old objects into a "waste basket" that hangs onto those objects and releases them at a controlled pace -- probably slowly at first and releasing them faster as the rounds progress and the waste basket begins to fill up. Or perhaps empty the waste basket at safe times, like the end of a round or at times when XanderCat has a solid advantage already. This would use more memory overall but may be far simpler and less error prone. I'm going to sideline my prior pooled objects work and try this route for XanderCat 12.7.
Sounds like it has potential, but isn't your primary GC issue at the very beginning of the match? Or did we already conclude that was intractable?
That might work, but I have my doubts. Unless you're calling System.GC() all the time it seems likely that the garbage collector will wait for a bunch to pile up and do it in bursts regardless of how controlled of a pace you release your references at (and calling System.GC() all the time would also likely cause it's own issues). I'd say the real solution needs to involve just plain not using so many tiny objects in the first place.
(It's kind of one of my pet peeves about Java, that the language encourages extensive object use, yet if you use it "too extensively" the code will have performance issues to due excessive allocation/deallocation overhead. In some languages (such as C++) one has the option of combining multiple objects into the same block of allocation, but because all object instances are references in Java there's no such luxury, ironically meaning that high performance java code needs to use simpler/fewer OOP structures than high performance C++ code in order to match the performance)
Also a pet peeve of mine about Robocode at this point. It has a really strict time limit per turn with a programming language that doesn't give you much control at that small of a scope. And even if it did, a rolling average would be soooo much nicer, and skipped turns are such a burden to deal with.
Automated garbage collection is about getting the job done faster/cheaper. Machine code always has more potential for performance than any language and/or paradigm. But in practice, due to overwhelming complexity issues, lower level languages tend to deliver worse software overall.
If you want high performance Java, increase the size of the heap, and/or change the ratio between regions, which solves 99% of garbage collection issues.
We could make it standard in RoboRumble to have a heap optimized for real-time. Using "-Xmn511m -Xmx512m" or "-Xmn1023m -Xmx1024m" in roborumble.bat would do the job very well. Not as fun as programmatic object pooling systems though.
Starting a new thread to discuss my efforts to deal with the skipped turn issue that is apparently related to garbage collection eating up allowed run time. This was previously discussed in thread "Shielding Success Rates Mystery", for anyone who wants to see where it all started.
I purposely did not contribute to the rumble over the last few days after the pairings for XanderCat 12.6 were lost. I originally ran many of the original pairings on my PC that does not have the skipped turns issue. Most of the re-run pairings were likely run by Voidious, whose system does exhibit the skipped turns issue.
The difference between the two is quite significant. With clients that don't exhibit the skipped turns issue, XanderCat achieved an APS of 87.7. With clients that do exhibit the shipped turns issue, XanderCat achieved an APS of 86.5. The difference -- 1.2 APS -- is quite significant. With the current rumble participants, it makes the difference between 5th and 8th place.
Most of the difference is due to the skipped turns causing the bullet shielding system to fail much of the time. But likely the skipped turns in general -- ignoring the bullet shielding -- also contribute a small amount.
I had previously fixed a few performance bottlenecks to make XanderCat run quite a bit faster (v 12.3), with much lower turn time peaks, but this only achieved a marginal improvement. I now need to shift to figuring out how to reduce the amount of garbage my framework apparently creates. This is not a real easy problem to address, because it is a very unique Java problem that rarely ever needs to be addressed in the real world, so there is not a lot of information or research available online to help on this.
I think one thing I can do is to eliminate as many intermediate local variables as I can. For example, variables with only method scope that are used to break something into multiple easier to maintain steps. These extra method scope variables may be contributing to the garbage collection, especially in the first round. Eliminating them may help to fix the problem, but at the expensive of either combining multiple lines together into more complex lines or making the variables have a wider than necessary scope (declaring them as part of the class), thus eating more memory overall but eliminating the possibility of it triggering garbage collection.
I don't know if these steps will help, but I will probably give it a try. I am also not sure if there are other ways to reduce garbage collection, but maybe I will come across some other ideas. I may actually create a second branch in my source tree for this work, something I never thought I would do for Robocode. I want to keep the current version, as I think it will constitute better code and perhaps someday the garbage collection issue will be addressed by changes to Robocode itself; but if my garbage reduction efforts work, for now I will operate off of a garbage reduced branch.
This seems like a really crappy thing to push onto you as a bot author. I do think our time is probably better spent coming up with a proposal to change Robocode itself and submitting that (as idea, design, or code) to Fnl. There could be a very simple and elegant solution that would work, like "allow 10x the CPU constant for the first 100 ticks". (Disabling CPU limits in first 100 ticks seems problematic, since you want to at least interrupt bots that hit infinite loops.) Another idea is having Robocode run its own GC cycle right before the match starts, in case bots are being penalized for GC of the game engine.
I'll try to get to another round of tests and find out how much I need to raise the CPU constant to get normal performance out of XanderCat.
I've had to deal with this quite a bit when writing games in c#. Similar to Java the GC can case obvious stalls. The easiest way is to stop calling the "new" function at run time by using pooling. For instance at the start of a match, or a round create a container object which contains N pooled objects which you know you create often, eg wave objects. At the point you wish to use one, take it from the pool, initialise it, use it, then return it to the pool when finished at any point later on.
Because you have not called new, and then nulled the object, the memory used does not go up, it stays constant, thus no GC is run. It's obviously impractical to pool everything so you just do the worst offenders which are things that you create often and throw away.
That seems like a great approach. And you can even create the pools in a static block, which I'm pretty sure runs before the match starts and won't count against any of your CPU time.
Speaking of static blocks, I've noticed that they get run on Robocode/rumble startup for every single bot, which is partly why it takes so long to start when there are lots of bots in the /robocode/robots directory. I also suspect that code in static blocks isn't subject to the security manager, since it can print to the main console. Does somebody feel like writing a test bot to see if this theory is correct?
Local variables are stored in the stack and not the heap, so they don't affect garbage collection.
You should look after "new" abuse, like Wolfman said. Although sometimes the instantiation is implicit and simply searching for the "new" keyword doesn't always work.
There are heap profiling tools which locate automatically where too many objects are being instantiated.
Local variables are stored on the stack but any time you use new it will go on the heap afaik:
public void MyFunc(Object a) {
Object b = a; // Variable b is on the stack, pointing at a. b = new Object(); // Memory allocated on heap, referenced by variable b on the stack
}
This is my understanding of it. Please correct me if I am wrong!
This is correct.
My understanding of the snippet above is that you have 3 variables. 2 local in the stack (references "a" and "b") and 1 in the heap (Object instance).
Some variables stay in the stack only, like primitives (double, float, int...).
Where would a primitive array like an int[] end up?
Java treats an array as an object, so on the heap.
However, these days the JVM is more intelligent than you guys are giving it credit for, eg. it has Escape Analysis to determine if objects should be put on the stack if they stay local.
Didn´t know about escape analysis.
What I usually do to take in account all optimizations, even those I don´t know about, is to use profiling tools. Measure what is really happening, instead of looking at the code and guessing.
I've actually been debating writing a Robocode simulator to make robot profiling much easier. What it would do is to pretend to run a robot battle with your robot against either another opponent, or perhaps some imaginary robot, using a combination of mock objects and simulation. It would run without any security at all, no sandbox, nor would their be skipped turns, so you would only want to run it with trusted robots. But it would be much easier to run a profiler against. The simulated battle may not be a perfect simulation, but as long as it's close, it should work and be useful.
When I do profiling in Robocode, I run a battle of a bot against itself. Then I filter the results by package so engine data is filtered out and only data from my bots appear in the profiling report.
Yes. However anything that you are creating during a function and keeping hold of for a few frames and then releasing is going to be allocating on the stack. Stuff like "Wave" objects, "Bullet" objects or whatever else you use in your bot will cause GC stalls if you create lots, use for a while and then null. This is where the pooling comes into force. I would definitely recommend pooling objects such as waves etc if you are having trouble with stalls and then go from there.
-wolfman
See, my bot always had a skipped turns problem, and now you're giving me a possible solution. You're drawing me right back in to wanting to start Robocoding again, dangit! *laughing*
Arrays are objects in java:
public void func() {
int[] myArray; // myArray variable on the stack myArray = new int[5]; // Array object allocated on heap, referenced by myArray variable on the stack
}
Note that member variables of objects are obviously going to take up memory on the heap not the stack - eg if you have 30 primitive member variables (ints, doubles etc) of a class and call new on that class, it will take up more memory allocation than a class that has 1 primitive member variable.
However allocating 30 local primitive variables during a function call allocates those primitive types on the stack alongside you local member reference variables.
While I am not the saddest person here that this has happened to you (as my robot is right above yours in the rankings with only a little APS between it and yours). But I know I would hate it if this happened to me. However I have tried to design things from the ground up in more recent robots to limit object creation and destruction.
At one point I even reused old objects (aforementioned pooling) instead of creating new ones. That didn't make it into the current version however.
I started doing some research on my shielding success rates. I started with a small set including Virus, Seraphim, Hydra, Crusader, and Engineer. I did a first test run of 20 seasons. Shielding success occurred on 20/20, 19/20, 20/20, 20/20, and 13/20 seasons respectively. I know why it's not perfect for Engineer, but the other 4 are the mystery. In the RoboRumble, my success rates on the first 4 are currently 5/8, 5/8, 5/8, and 4/7 respectively.
None of the Rumble losses were run by my machine. But all of them were run using client 1.7.3.0. Losses only occurred when run by Voidious and DivineOmega. I'm guessing there is something common about the machines used by you two that is key. Are you both perhaps running under Linux? Also, what version of Java? I need to replicate one of your machines as closely as possible to explore the problem further.
Maybe their clients are skipping turns. Missed scans hurt bullet shielding a lot.
If they want to check that, they sort-of can. It only reports on the last battle that it happened, but if my robot has any skipped turns, it will write a file xander.cat.XanderCat_SkippedTurns.txt file into it's data directory that has the number of skipped turns printed in it. It's not as useful as it could be since it just reports on the last battle that it happened on, but could be worth a check.
Are the tests you run also using 1.7.3.0? (BTW, I'm doing some major bullet-shielding-suffering at the moment...)
My rumble clients are on a Core i7-3770 running Ubuntu 12.04 (32-bit), and I think OpenJDK 6 (will check when I get home). Now that you mention it, I recall a similarly huge discrepancy for the original BulletCatcher on an old AMD Ubuntu machine I was using as a rumble client (couldn't find the discussion though). I chalked it up to the different JVM or even the CPU and ended up just retiring the machine as a rumble client, since it was a fraction of my overall CPU power.
My first guess is that when two bullets are close enough to parallel, one JVM's Line2D says they intersect and another doesn't. I actually have Ubuntu 32-bit, 64-bit, and Windows 8 64-bit all on that same machine, so I should be able to do some decent tests for you with only the JVM or OS as a variable.
Found the discussion: Archived_talk:User:Voidious_20110909#Wierd_scores
When the opponent is moving, my robot stands perfectly still (it rotates but doesn't move position). Thus, I haven't verified it, but the two bullets should be perfectly parallel, and this is likely handled differently on different JVMs as Voidious was talking about. However, when both robots are standing still, my shielding shot will miss, so my robot will move slightly when firing a shielding shot against a stationary opponent. I haven't had enough time to figure out what causes this, but I wonder if the answer will give any further clues. I did it this way because it worked, but more investigation is required for me to figure out why.
I could play around with moving slightly for every shielding shot (and moving back right after the shot). I tried this briefly, but found standing still to be more reliable on my machine. But maybe I can tweak it to where it works as well as standing still. If I can, I bet it would avoid the problem.
I will likely need a few more days to play around with this further. In the meantime, if Voidious has time to try out the other JDK, that would answer another piece of the puzzle.
Standing still works because the enemy gun rotation happens after the bullet is fired, so they shoot from a position of 1 tick ago but use their aim from 2 ticks ago. So if they are moving their angle to you changes and they don't quite shoot at your centre, meaning that you can get your bullet line to intersect with theirs because your bullet comes from your centre (which they aren't aiming for). This is also why it stops working when they stand still, because their last position relative to you lines up with their current position relative to you so you end up shooting parallel.
I'm trying to figure out why my super-advanced precise circle-line intersection methods are failing so horribly at getting shield hits. I get one every now and again, but nothing like what I should be based on the maths and shield size I'm calculating, and nothing like the 3/4 of bullets that a simple linear projection + bullet power adaptation was getting.
I would recommend against using Seraphim in a test bed. It is a very buggy robot. So much so that I think it sometimes acts differently in a rumble environment then in a test environment.
But also some versions of Seraphim if I recall add a minor variance to its gun heading it detects it is against a bullet shielder. Is the version your using the same as the one in the rumble? (I expect so, but it cannot hurt to ask.)
After some testing, maybe we can come up with a more consistent implementation for checking bullet collisions / line intersections in the Robocode engine. Here's the relevant code snippet: [1] (line 76 calling line 113).
Here's one that gets rid of the division which I expect is what blows up on poorly conditioned problems:
private boolean intersect(Line2D.Double line) {
double x1 = line.x1, x2 = line.x2, x3 = boundingLine.x1, x4 = boundingLine.x2;
double y1 = line.y1, y2 = line.y2, y3 = boundingLine.y1, y4 = boundingLine.y2;
double dx13 = (x1 - x3), dx21 = (x2 - x1), dx43 = (x4 - x3);
double dy13 = (y1 - y3), dy21 = (y2 - y1), dy43 = (y4 - y3);
double dn = dy43 * dx21 - dx43 * dy21;
double dn_sign = Math.signum(dn);
double dn_abs = dn*dn_sign;
double ua = (dx43 * dy13 - dy43 * dx13) * dn_sign;
double ub = (dx21 * dy13 - dy21 * dx13) * dn_sign;
return (ua >= 0 && ua <= dn_abs) && (ub >= 0 && ub <= dn_abs);
}
It might even be faster, divisions are about the same speed as sqrt.
Given that it is using it's own code to determine intersection rather than a JVM method, I wonder if the discrepancy between systems is actually in the data stored in the line objects.
I thought maybe I could tweak it using a small amount of movement to make it work on all systems, but so far my attempts have degraded shielding performance unacceptably. One bit of good news -- I tested and found out that Robocode security does not prohibit robots from reading System properties, so if I can figure out how to correct (at least partially) for the problem on other OSs or JVMs, I can test for them and just make those changes on the appropriate systems.
When I experimented with bullet shielding, my bot calculated minimum and maximum angles which would hit an incoming bullet, and only shoot if the difference between angles was above a threshold. It was there to work around floating point calculation errors, which translate into "parallel" bullets.
If the difference is below the threshold, then moving sideways helps increase the difference. Near 100% bullet shield against TrackFire. But against moving opponents and/or weak powered bullets, sometimes my bot moved until it crashed on the wall, never finding a good angle to shoot. And this is where my experiments are stuck right now.
Tonight I ran a test on one of my servers in my basement. The OS on it is Fedora 13. I installed Open JDK 6 (command su -c "yum install java-1.6.0-openjdk-devel"). Once installed, it reports itself as:
OpenJDK Runtime Environment (IcedTea6 1.8.8) (fedora-51.1.8.8.fc13-i386) OpenJDK Client VM (build 14.0-b16, mixed mode)
I ran a number of battles and have yet to encounter any shielding failures using XanderCat 12.2. But I need to do a more thorough test to be sure. Tomorrow I will set up RoboJogger and run a bigger series of tests.
Just checked and I'm also on OpenJDK 6:
java version "1.6.0_24" OpenJDK Runtime Environment (IcedTea6 1.11.5) (6b24-1.11.5-0ubuntu1~12.04.1) OpenJDK Server VM (build 20.0-b12, mixed mode)
Sorry I didn't get to any real testing today, but I will tomorrow. Now I'm really curious to see if I see the same in another JVM or in Windows...
In case it's easier just to copy it from here -- here is a challenge file with 3 opponents that XanderCat 12.2 is nearly perfect against on my machine but only maybe 50 percent successful against on machines that exhibit the performance anomaly.
Shielding Vulnerable
PERCENT_SCORE
35
Shielding Vulnerable {
apv.test.Virus 0.6.1
kc.serpent.Hydra 0.21
trab.Crusader 0.1.7
}
I finally got my precise intersection with bullet shadows working for bullet shielding, so Voidious, if you're going to run some tests to see if bullet collisions work on your machine, give this a try as well: https://dl.dropbox.com/u/4066735/jk.precise.BulletShieldTest_1.0.jar I'm theoretically getting around half a pixel of shield width, so if that doesn't work then there is something seriously wrong.
Hi mate.
I was in the mood to check XanderCat 12.2 on my system and maybe it can help you to detect some uncertainties.
Mac OS X 10.6.8 java version "1.6.0_37" Java(TM) SE Runtime Environment (build 1.6.0_37-b06-434-10M3909) Java HotSpot(TM) 64-Bit Server VM (build 20.12-b01-434, mixed mode) Robocode version: 1.7.4.4 CPU constant: 5426594 nanoseconds
Result vs Virus (png) Last Round Log vs Virus (png) Round start log vs Virus (log)
{kind=link}
{kind=link}
I started a couple of runs and it looks like almost 50% failed because of massive skipped turns if the round starts. This happens if the client runs on low speed and as well on full speed. If I put the client on debug=on, everything works fine and XanderCat win all rounds like expected. Because of the skipped turns XanderCat misses quite a few bullet catches and decides to move with a different movement - from that point he is almost ever doomed to loose some rounds. I hope it helps a little.
BulletShieldTest 1.0 worked so far very good on my system. He is lost against all 'sloppy' guns (HawkOfFire,SpinBot..) but against well coded targeting he has a quite impressive performance. Of course, he has still some minor flaws but i guess that is not unusual for a test version.
All in all i would say there is no difference in how the JVMs handle intersection but there may be a difference how they handle garbage collection and therefor have a different skipped turn behavior.
Man, I wished I had more time these days :( - take care
Thank you, Wompi. That is very helpful. From the round log, looks like there are occasional skipped turns (most likely due to the wave surfing drive and guess factor guns, but these sit idle when bullet shielding is active, and bullet shielding is much less processing intensive). However, the first round where most things are initialized is the worst.
So it's probable the problem isn't with the JVM doing the shielding calculations but rather how much time each system is allowing and how long it takes my initialization code to run (which I can work on, but it may also be true that different JVMs take different amounts of time for different types of initialization).
Looking at the info provided by the run time loggers, the averages between my system and yours aren't all that different, but the peaks shown on yours are an order of 5x what they are on mine. The radar peaks are even worse, which is weird. A typical greatest peak for my radar on my system is 0.25 trialing down to less than 0.1 by the 3rd peak, whereas on your system they start at 9.9 and are still above 0.8 by the 5th peak. (note: peaks are over the entire however-many round battle, as are the averages)
Both your system and Voidious' system are using the Server VM, and that makes me suspicious. I need to try out a Server VM and see what happens.
It should be noted that if this is the problem for Voidious, DivineOmega, and perhaps others, it is affecting overall performance (in the first round at least) and not just on the bullet shielding. If I can find a way to fix it, overall rumble performance could improve some.
Running some tests now. Starting with 20 seasons, single-threaded on the Ubuntu/OpenDJK setup. 10 seasons in and see it failing a lot vs Virus (~76%), rarely vs Crusader (~90%), and working well vs Hydra (96%). I'll post more details and the full RoboRunner logs when I've got some more data, and try it through the UI to see what I can tell about skipped turns.
If it is a skipped turns issue, I know there is one trick to put heavy initialization stuff in a static block and it won't count against your CPU time. I really hate Robocode's skipped turn setup, though I think limiting the CPU time in general is great. I'm definitely taking a different approach in BerryBots. It's probably too late to completely change it in Robocode, but we could at least look at an average over the last 5 or 100 ticks and penalize based on that instead (which is part of what I'm going to do).
Wow, ok.. So 4 threads was slightly worse overall, but 20 seasons is hardly enough to cover the margin of error. Now testing on Windows, and at 98 overall score after 8+ seasons. This is Oracle Java 7. Also interesting to note that the CPU constant was set to about 5 ms in Windows, vs 7 in Linux. Also this is all on Robocode 1.7.4.0, sorry about that, but I don't think it makes a difference.
Ok, still want to test on Ubuntu 64-bit and with the Oracle JVM on Linux, but here's a bunch of data for now.
| config | Virus | Hydra | Crusader | Total |
| Linux/OJDK/1 thread | 76.14 +- 8.29 | 95.93 +- 0.37 | 89.26 +- 5.17 | 87.11 +- 2.66 |
| Linux/OJDK/4 threads | 81.45 +- 7.6 | 82.77 +- 6.51 | 90.91 +- 5.14 | 85.04 +- 2.92 |
| Windows/1 thread | 98.89 +- 0.25 | 96.09 +- 0.33 | 98.67 +- 0.34 | 97.88 +- 0.17 |
| Windows/2 threads | 97.18 +- 1.91 | 96.31 +- 0.35 | 98.92 +- 0.3 | 97.47 +- 0.48 |
| Windows/3 threads | 95.4 +- 3.19 | 96.39 +- 0.23 | 88.88 +- 5.49 | 93.56 +- 1.55 |
| Windows/4 threads | 98.66 +- 0.31 | 92.2 +- 3.5 | 92.42 +- 4.31 | 94.43 +- 1.41 |
It's worth noting that I feel comfortable running my own benchmarks 6-threaded on this machine and I usually run 4 RoboRumble clients at a time.
Thank you, Voidious, for all the data. Don't forget to take a peak at skipped turns under Linux/OJDK. It gets printed to the game log, and you can also check what is printed in the SkippedTurns text file it writes to the data directory.
For now, I'm going with the assumption that I need to target reducing initialization overhead due to skipped turns. Once I have that done, I can prepare another version of XanderCat, which if I'm lucky you will be willing to run through your Linux/OJDK setup again to see how it changes things.
So, upon not getting to the bottom of this, I stopped running my rumble clients. Where are we with the discrepancy in shielding success on different systems? I don't particularly mind keeping my clients off for now, since I'm not submitting bots, but I do have quite a bit of CPU power I'd be happy to contribute.
I also still want to test with the newer XanderCat, Ubuntu 64-bit, and a different JVM on Ubuntu, but that requires Voidious-time and not just CPU-time. :-)
Not much new at this point. I greatly reduced my processing overhead in XanderCat 12.3+ in an attempt to improve on the problem (nearly cut average and peak processing times for targeting and surfing in half; see Version CPU Usage section of my XanderCat page; noting that my CPU constant is around 10ms), but since the problem seems linked to garbage collection, I don't think it will result that much of an improvement (I'm guessing far fewer skipped turns in later rounds but still a bunch in the first round, which will still break shielding). I may be able to reduce the amount of garbage collection by trying to eliminate as many local method-scope variables as I can, but that would be a lot of work for something that will likely make the code less readable and I don't even know for certain if it will help. Thus I haven't tried it yet.
Wompi indicated that using -XX:+UseConcMarkSweepGC to use the concurrent mark and sweep garbage collector eliminated the problem, but I don't think anyone was sure whether it was a good idea or not to use this as a solution. Not sure if it could cause other problems.
For now, I don't mind if you restart your clients. XanderCat 12.5 already has over 10K battles and I don't intend to replace it with a newer version for awhile.
I'm curious, what method are you using to determine that your shielding isn't working? Do you just stop after a certain number of bullet hits/bullet damage?
Mine is a rather complex set of conditions, some that can happen on and off and some that can effectively disable shielding for the rest of the battle.
I'm guessing you are more interested in the conditions that that turn it off for good. That determination takes into account total bullet shielding misses, consecutive bullet shielding misses, average damage taken per shielding shot (presently it assumes all misses will result in damage, but I've been contemplating changing this to only when real damage occurs), overall shielding success ratio (total shielding hits / total shielding shots), and round number (some things more lenient on earlier rounds).
More temporary on and off conditions include stuff like rolling average opponent fire power, opponent distance, round time, whether or not the opponent keeps not firing first, and whether or not a shielding shot was just missed.
If you want to see specifics, you can dig into my code and look at the big nasty condition starting on line 123 of BulletShieldingScenario. It just might be the biggest condition statement I've ever written. I need to do more research to figure out how often any of those conditions are actually triggered to fine tune it all and order the conditions to minimize processing required, but I don't expect a lot changes, other than cleaning up the class so it's not so messy.
Here I am going to post information on CPU performance of configuration, construction, drive, gun, and radar. Configuration is one time setting of parameters at beginning of first round. Construction is construction of the scenarios, drives, guns, etc. and loading them into my component chain, also a one time event at beginning of first round. Load stats is loading the previous set of statistics from disk so they can be updated and written back out at the end of the battle. Drive, gun, and radar times are averages and peaks over every tick for the entire battle.
In all I ran averages against 10 seasons.
12.2 is XanderCat 12.2, while 12.3 is the development version of XanderCat 12.3 with whatever CPU performance improvements I can make. Originally I was going to focus on trying to improve initialization, but since turn 0 apparently wasn't getting skipped, I decided to focus on drive and gun improvements instead.
| 12.2 Normal | 12.2 Shielding | 12.3 Normal | 12.3 Shielding | |
|---|---|---|---|---|
| Opponent | Tron | Virus | Tron | Virus |
| Configure AVG | 0.454 | 0.478 | 0.459 | 0.469 |
| Construction AVG | 1.304 | 1.353 | 1.306 | 1.310 |
| Load Stats AVG | 3.730 | 3.686 | 3.690 | 3.321 |
| Drive AVG | 0.478 | 0.031 | 0.299 | 0.016 |
| Drive P1 | 12.51 | 5.25 | 7.34 | 3.82 |
| Drive P2 | 11.91 | 4.70 | 6.95 | 3.18 |
| Drive P3 | 11.46 | 4.55 | 6.81 | 2.99 |
| Gun AVG | 0.465 | 0.153 | 0.267 | 0.082 |
| Gun P1 | 7.12 | 7.17 | 5.23 | 5.84 |
| Gun P2 | 6.03 | 5.13 | 4.44 | 4.09 |
| Gun P3 | 5.65 | 4.26 | 3.77 | 2.66 |
| Radar AVG | 0.0019 | 0.0018 | 0.0018 | 0.0018 |
| Radar P1 | 0.10 | 0.28 | 0.07 | 0.35 |
| Radar P2 | 0.06 | 0.14 | 0.05 | 0.05 |
| Radar P3 | 0.04 | 0.04 | 0.03 | 0.04 |
I hadn't thought about it previously, but I can't help but wonder if the loading of battle statistics is one of the bigger problems with skipping turns at the beginning of the first round. On my system, the CPU hit is not all that dramatic, but it could be worse on other systems. Maybe I could defer loading the battle stats until the end of the battle? They are not really needed until the end. How much time does Robocode give at the end of battle for final processing like writing to files?
I can think of 2 factors which can mess up skipped turns. Dynamic overclocking and excessive amounts of client instances.
- Dynamic overclocking changes CPU speed based on load. If the Robocode engine CPU constant is calibrated for an overclocked CPU, then in the beginning of a battle, the reduced clock will provoke skipped turns.
- Too many client instances make them interfere with each other. Sometimes clients use 2 threads, sometimes only 1. When they use 2 and there isn't any idle core, they steal CPU from another instance and the slower processing speed can provoke skipped turns.
Some thoughts...
- For what it's worth, I tried to generate different CPU constants based on whether it was dynamic overclocking or not, but wasn't able to. Maybe the trigger threshold is well below what a single Robocode instance or the CPU constant calculation uses on my machine.
- While Robocode does use multiple threads - you might see 50% on two cores or 100% on one core - it only uses 1 at a time, so I'm not sure it's ever really stealing CPU.
- Since a lot of modern multi-core processors include hyperthreading, there should be some extra buffer such that using 1 Robocode per core is ok.
To me, the bigger problems are:
- Measuring CPU time for a single tick in nanoseconds is not nearly as accurate as we need it to be.
- There's always other system stuff that could use some CPU. Combine with the lack of accuracy and it's really dangerous to penalize for taking too long over a timeframe of just one tick.
I don't know, I agree that dynamic overclocking is theoretically a concern, but from what I can remember, skipped turns have been quirky since long before we all had huge multi-core machines with hyperthreading and dynamic overclocking.
Quirky like skipping more turns vs an opponent that uses a lot of CPU (but doesn't skip turns!), or skipping lots more turns in the first 50-100 ticks of a battle. Obviously you do some initialization in the first tick, but shouldn't the subsequent ticks be mostly unaffected by that? Seems like that was never the case and still isn't. I guess garbage collection being outside of the scope of Robocode's vision is the most likely culprit for all this. But it's pretty frustrating, in any case.
That's a good point I wasn't even thinking about. Looking at the log Wompi posted again, I can see that all setup was completed on turn 0, and turn 0 wasn't skipped.
Voidious -- did you check to see if XanderCat appeared to be skipping a lot of turns on your Ubuntu/OJDK machine?
I can try to improve the CPU performance of my wave surfing drive and guess factor guns, and that might help, but it doesn't really explain the huge number of skipped turns on the first round. In the meantime, if skipped turns is a problem on Voidious' machine, I suppose for now I could just modify my bullet shielding system to try to account for skipped turns.
Remembered a 3rd possible cause of skipped turns. The JVM executes all code in interpreted mode for a while until JIT compiler kicks in. And at least in Sun/Oracle JVMs, the default JIT mode, client or server, varies with OS.
Hmm... frustratingly, XanderCat seems to have a higher success rate vs Virus (the most problematic on my system) when running through the UI. I did catch one 56% score with only 2 skipped turns, though, which raises some doubt that skipped turns are the issue (or only issue). Running some more single-threaded seasons with RoboRunner now, in case it's something like a fresh reboot helped (after testing in Windows earlier).
I thought once about Robocode being more multi-thread friendly if the engine called Thread.yield() in strategic places, like between ticks. But I never posted this suggestion in sourceforge.
This way, most processing outside a Robocode instance would be done between ticks and not interfere with turn skipping.
About dynamic overclocking, here I delete config/robocode.properties and run a single instance, which will measure CPU constant at minimum possible speed. Then I copy the file to all other installations. Tried to disable dynamic overclocking as well, but my laptop doesn't have the option in the BIOS.
Hi mates.
We had once a quite long discussion about skipped turns (Skipped Turns) and I remembered this gc-tuning page. I played around with some of the gc settings and it generated a very different robocode experience. To sad, I don't have the time right now to provide some serious tests but maybe it gives someone a hunch to find some appropriate settings for the gc.
One other thing, do you look out for 'hidden' skipped turns or just take the skipped turn events?
My overall guess would be, that initialization is not a big problem and could easily detected if you spot skipped turns at the start of the round (I remember DrussGT had once an issue where he skipped the first 10+ turns). It is more likely that bots generate a bunch of initialization objects and this bunch of objects get garbage collected a couple of turns later (lets say turn 30+) and that would be the time where it hurts most. Of course this is just a wild guess and i could completely wrong but it could be one explanation why quite a few bots have issues with skipped turns mainly within the first round.
I think another reason the first round is difficult is that the JIT hasn't yet optimized code, but also a few ticks later the JIT figures out which code needs optimization and then starts running the compiler in a parallel thread. This competes with the robot time, so not only do you not yet have optimized code, but the time is also being shared with the JIT compiler. This would also explain skipping turns starting a few ticks in instead of on the first turn. Also, the more code you have that gets run regularly, the more the JIT will try to optimize, so it will take longer and possibly cause more skipped turns.
Well, I couldn't hold it and had to run some tests.
I tested all three collectors on XanderCat 12.3 vs Virus and Diamond vs DrussGT
-XX:+UseSerialGC
DvsD: both bots dropped turns like crazy and DrussGT almost ever won with 64% APS
XvsV: XanderCat dropped constantly turns over all battle rounds (sightly more on the first two rounds) and lost quite a few rounds against Virus
-XX:+UseParallelGC -XX:+UseParallelOldGC -XX:MaxGCPauseMillis=1
DvsD: both bots dropped even more turns than with the SerialGC - DrussGT still won with 64+% APS
XvsV: XanderCat dropped a lot turnes in the first round and some in the second - all other rounds had no skipped turns (because of the crummy first round he took the wrong movement and lost a bunch of APS vs Virus)
-XX:+UseParallelGC -XX:+UseParallelOldGC -XX:MaxGCPauseMillis=30
DvsD: less skipped turns for both but still to much - DrussGT still on 64% APS
XvsV: no changes to 1ms pause
-XX:+UseConcMarkSweepGC
DvsD: DrussGT drops a turn here and there - Diamond still drops a lot turns but with a lower frequency - DrussGT wins with 50-55% APS
XvsV: XanderCat stops dropping turns at all (just a few here and there) and wins against Virus with 99%
I also changed some other ratio settings but could not see any visible changes to the overall behavior. To me the concurrent collector looks quite promising and I think I play a litlte with the CMSIncremental.. options to see if there is still room for some improvements.
Very interesting. Thanks again for all the testing. Even if the issue can be fixed by GC settings, maybe I should look to see if I can make my robot more environmentally friendly and stop producing so much garbage? My first thought turns to the way I pick data out of my KD trees (because I sloppily move all data points from a MaxHeap into a List in order to stick to my existing interface, and that List gets created and thrown away on every tree read), but I'm not sure that would help on the first round issue.
Wow! Great research here. I wonder if you enable incremental mode for the concurrent mark sweep GC using -XX:+UseConcMarkSweepGC -XX:+CMSIncrementalMode how that would work. Also, the concurrent collector uses additional cores to do the work, so might not work so well unless there are cores free. Of course, designing a bot so that it is resistant to skipped turns, and uses little CPU and memory, is probably the most important aspect of all.
Uh, I wouldn't change anything in this direction. It was just a quick test (<10 seasons) and I doubt it solves anything. To me it just shows a dependency and might worth further test. I'm still convinced that another skipped turn handling (like Voidious suggested) would be far better. Maybe raising the cpu variable for rumble clients would be a workaround - but this would need that everyone develop his bots within the normal cpu range and not abuse this workaround. Probably not a good idea but like many others I get more and more annoyed by the skipped turns because it complicates even very simple tasks.
I did a little reading on the garbage collector looking for information on how I could reduce my garbage collection footprint. Short of stripping things out of my robot permanently, I did come up with a few things I could potentially do to reduce the amount of garbage collection. I'm going to try to implement some of it, but it's just guesswork as to whether or not it will actually improve things or not.
The recommended garbage collector for real-time applications is the copy collector. Or the treadmill collector, which is a variation of the copy collector.
All JVMs have the copy collector, but only for young objects. You can make it being used for all objects by increasing the young generation size. Set -Xmn<value> to the highest value the JVM allows, like "-Xmn511M -Xmx512M" and the copy collector will become the main GC. There are other parameters as well, but I can't find them right now.
Anyone know where to find the fast math pages/discussions? I did a search on "fast math" and couldn't find it. I know there was a number of places where alternate code for doing various trig functions was discussed, but I can't find them now.
I think it's User:Rednaxela/FastTrig.
(I didn't really notice any speed improvement when I tried adding it to Diamond, so I removed it, but maybe I screwed up or it would help other bots more.)
With Combat, profiling said all trigonometry added together were consuming about 8% CPU time. Dropped to less than 3% after fast math classes were added. Not too much of an improvement, but it was an improvement.
Thank you. I may give it a go. In the meantime, I've figured out how to make a few significant improvements that reduce the number of trig functions used. In particular, I have a method in my robot predictor that calculates sin and cos for every predicted robot movement; revising it to only recalculate sin and cos when heading changes actually made a significant improvement.
This version is like a fresh breath of chaos. Oh, the mischief I'm causing. :P
One of the few altruistic bots: beating the strong and helping the weak ;-) But the overall result is ok, closing in on Dookious. If you can find a way to rule out those 98->75 scores you'll be close to #3 and way ahead of me.
Nice work!
Though it looks like you still have a few bugs in your specialized modes. A 26% score against GeomancyBS is almost as bad as 70% against Idem (a nano with Linear Targeting).
UPDATE: Version 12.2 is much better against those two bots.
Really nice work, congrats! I wonder if you've got Skilgannon thinking that maybe Bullet Shielding is the gateway to 91 APS - I know I'm thinking it. :-)
Thank you. I really didn't expect to see such success with adding a new mode to XanderCat. But after a lot of work unsuccessfully trying to improve the main surfing drive, I have to say I'm most pleased with it. :)
I'm also surprised how much it helped. I also think there might be scope for the opportunity to open up a shadow enough to completely hide in it with regular surfing, rather than just have a separate mode. And to get the full magnitude of the improvement, I think this diff is more relevant, and even more impressive. Never mind 91APS, 92 could be a possible target.
Speaking of bullet shadows, I think active shadowing could be possible in a 1000/1000 field. It could be used in Melee endgame duels to great effect. First, check if a full shadow is possible, if it is, then fire a low power bullet to create the shadow and move accordingly. If a full shadow is not possible, then just surf and fire normally.
One problem I could see with this is that you might not gain any energy by firing 0.1 bullets, because at long distances in endgame, 0.1 bullets are pretty regular. Also, with the enemy also shooting low power, you won't have much advantage in distance ratios to get a wide shadow because of bullet speed differences, but with enough distance that shouldn't matter that much I guess. Hmm. Food for thought...
I'm not sure that's true (edit: active shadowing more effective on larger fields). Being far away means the shadow has had time to grow, that's true. But another key to creating big shadows is for the bullet/wave intersection to happen as soon as possible after the enemy wave is fired. The farther away you are, the harder it will be to do that with any precision. It might be more effective to stay close and create accurate shadows than to gamble from far away.
Edit: Sorry, my argument kind of misses the point. With Robocode accel/decel, it's more about giving yourself enough time to get there. So I think you're right.
I don't understand, I thought as long as there was a 36px area within reach that could not possibly be hit, a bot in that area would be completely safe.
I wonder if this full shield idea is applied in teamrumble. 1200x1200 battlefield and 5 simultaneous shots which can be coordinated to create huge shadows.
It isn't, but it sounds promising. It could also work in twin duel: take out the weak enemy then have your two bots shadow/shield each other until the enemy leader runs out of energy.
This would be tough in Twin Duel with the code size restriction. But I think MegaBot 2v2 would be interesting at this point.
Not necessarily. Make both bots instances of the same class, give them Waylander's gun, fire 3's at the enemy grunt until it's 1v2, then have them hide in corners and shield each other every time the enemy fires. I believe Rednaxela was planning to try something like this. Let's beat him to it! :)
In team battles, there is the added complexity (and fun) of needing near perfect team radar locks to make bullet shield viable.
Provocative movement, which owns bullet shield, is also a greater threat in team battles than it is in 1v1.
Neuromancer does 'bot-shadows', where if a wave passes over an enemy, the section that the enemy covered is marked as safe. Unfortunately it didn't help in terms of score, I suspect that my wave locations and firetimes aren't accurate enough. Also, if the wave was fired far enough away that it passed over another bot it probably wasn't weighted very highly anyway.
In the old days of robocoding, 'bot-shadows' were called bomb sheltering.
One bad thing is that there is a lot more volatility in the score, based on whether or not the "scenario" (my terminology) correctly identifies which opponents to activate against. And the score difference can be huge. While in the past the Rumble score was pretty stable after about 2000 battles, I would say it now takes more like 6000 to 8000 battles. Watching the progression on version 12.2, after about 1200 or so battles the APS was around 86.85 (excitingly close to WaveSerpent), but now with 3800 battles it has dropped to 86.50, in danger of dropping below Dookious after such a solid first showing. I still don't think we can say whether or not it will level out above or below Dookious.
It should also be noted that the effectiveness of bullet shielding will be less if implemented by top surfers. The score boosts will be less against the vulnerable, and there is more opportunity to lose performance against the non-vulnerable.
I also have to take an extra step in future development. Due to the volatility, whenever I am working on anything but bullet shielding, I have to disable the bullet shielding mode to get more reliable testing results.
I know I am kind of focusing on the downsides here, but I think the upside is pretty obvious, thus I am commenting on the more subtle issues this new mode introduces.
After looking at the individual battles against a number of opponents, I might add that with more testing and time, I can probably improve the scenario to activate a little more reliably against vulnerable opponents. This could eliminate at least some of the volatility and possibly give another 0.2 to 0.3 APS boost (assuming 12.2 holds around 86.5). I will have to create a challenge of shielding vulnerable opponents and collect more diagnostics to see which of my conditions for continuing bullet shielding are occasionally violated and why; then I can hopefully tweak it a bit to make detection more reliable.
I've actually been thinking about this. It's not possible to know how well you can dodge their targeting without risking poisoning their targeting into shooting non-GF0 bullets, which makes it difficult to know against bots that you can dodge perfectly if they are secretly a Hydra, and the 97% is a 30% increase in possible score, or if they are just DoctorBob and the 97% is a 3% decrease in score.
0.35 is a lot after 2k, and I would certainly buy that this increases your volatility, but I'd wait and see if future versions behave similarly to say for sure. I've seen lots of variance above 2k battles with lots of bots, not just after adding sensitive multi-mode stuff. It was something I never really noticed until we had a surge in RoboRumble power from KID's clients and bots started actually getting to 5k-8k battles. It could have also been something like a few enemy bots crashing/skipping turns on one client and then behaving normally on another client that started up later.
I tried the top bots that came to mind and at first couldn't find any over 55k. But apparently you didn't quite set the record (but close). Only kept highest for each bot.
java -jar robocode_1.07/codesize.jar ./robocode.rumble_1730/robots/*.jar ... 45842 293199 74 kid.DeltaSquad.DeltaSquad_.1.jar 46143 289610 77 kid.Gladiator_.7.2.jar 47086 335204 209 Homer.Barney_1.0.jar 47269 458846 232 pedersen.Grishnakh_1.0.jar 50883 406124 107 voidious.Diamond_1.7.24.jar 52283 147604 107 positive.Portia_1.26c.jar 54049 307732 92 florent.XSeries.X2_0.17.jar 54352 249048 48 aw.Gilgalad_1.99.5c.jar 55297 509698 190 xander.cat.XanderCat_12.0.1.jar 58387 139768 35 jk.mega.DrussGT_2.8.8.jar 227423 474856 62 Krabb.sliNk.Garm_0.9y.jar
Not sure what the heck is going on with Garm! :-) Maybe he includes some big external library? I know I've thought about pulling in Guava, though there are ways to only pull in what you use.
Does he have the largest class size though? Speaking of codesize, I tried my hand at rewriting the tool.
I think I have to throw in some extra bytes to the 12397 I use now, and pass Phoenix before you do. But hey, I am no Java programmer, for the current assignment I use OOPerl . . .
I don't particularly care one way or another, but I also don't take pride in my large code size. It's worth noting that a laughable ~10k of Diamond's code size is the perceptual gun he uses for the first few shots. :-) Factoring that in, I don't think Diamond's too bloated for a full-featured 1v1 and Melee bot.
Heh, after Garm DrussGT comes in second =) I suspect it's because I have several Precise Prediction methods, my pixel-perfect Waves/Precise Intersection ones for first wave calculations and my high-speed ones for second wave calculations, and then I still have all of the code for the precise predictions which tracked when an enemy would fire and what segments they would see even though they aren't being called. Also, all of those buffers that are hard coded add ~17000 codesize.
I was looking into building an AS gun using spectral clustering, and when I packaged it, it pulled in the entire Colt library, which brought DrussGT to 217374 codesize bytes and 760KB of jar file! Needless to say, I started looking at other matrix libraries...
Anyone have a huge challenge file they can post or send to me that includes a large number of rumble participants (anywhere from 100 to 1000)? My biggest one contains 58 opponents and it still sucks bigtime. Okay, call me lazy, but I haven't been willing to hand type out a challenge with hundreds of participants, and I can't access the query API and therefore can't use the test bed maker. I feel like I am abusing the Rumble a bit because of these things, releasing more versions of my robot than I should. Before I go spend an hour or more hand typing out a challenge or writing my own tool to build challenge files, I'm hoping maybe someone just has one they can provide for me? Or maybe someone with Query API access can run a test bed for me?
I'd be happy to run BedMaker for you when I'm home this evening (and/or post some of my bigger .rrc files). Until then, you could try the ones I ran for User:Tkiesel a while back. [1] [2] ("150 bots that deBroglie rev0108 scores 57-95 against")
I'm sure some bots are not currently in the rumble, so it's possible you'll be missing some.
I could get by on those, but if you run me one, I'm thinking maybe 250 bots that XanderCat scores 0-95 against.
Muahaha. It will take forever to run, but by goodness, maybe it will actually be useful this time! Thank you!! Now if I can just figure out how to justify upgrading my old Core 2 Duo with a top of the line i7 processor...
Wow. That looks a lot more advanced than I thought it was. I've actually got a Linux server in my basement that I use as my network storage (no media streaming, just backup) and code repository, but otherwise it does nothing. It's not that powerful, but since it mostly sits idle, I will look into setting it up as a node for distributed Robocode.
Ok, say if you setup it - then i configure portforwarding, so you will available connect to my DR servers
I'm still planning on doing this, but it might be a couple more weeks. When I went to my basement to set up the server, I noticed the CPU fan had stopped working. This is not really a problem with the CPU mostly idling as it does now, but if I set up Distributed Robocode on it, I need a working fan. I'll be putting a new fan on it sometime in the next couple of weeks, after which I can get Distributed Robocode going on it.
No problem, and good luck! As for the Robocode-inspired upgrade, I gave up on justifying it and just did it last summer. :-)
I start write Robocode Development Kit this month and currently it's just can download all participitians and genereate challenge files. There're no public available builds, but you can see project here: [1]. If you interesting, i can upload build of it for you.
Frequent resubmits to the rumble were annoying me in the past.
But now I use a custom priority battles algorithm which places my bots above others until they have about 15 battles per pairings. :P
After that it resumes normal priority battles driven by the server.
So I've put a lot of time in on XanderCat, what is supposed to be version 12. Wow is it hard to improve at this point. I had roughly 10 new ideas for improving and all of them had no positive effect. The only improvement so far has been in some refactoring I have done, which has simplified a few things, but not changed my score any. There are a few instances of robots that some other top competitors score nearly perfect against, but XanderCat only gets maybe 85 or 90. I think I may figure out how to make some improvements by closely scrutinizing those instances. I also want to take a closer look at each of my special case scenarios to ensure none of them are counter productive -- this includes my ram escape scenario, anti-mirror scenario, my targeting detector drive engagement scenario, and my bullet shielding protected gun wrapper. I don't expect to find anything wrong though; probably will just be verifying that they work as intended. Ho hum...what next...it seems like there should be some big gains to be had, given XanderCat is still 5 APS behind the leader, but darned if I can find them. I'll keep trying when I have the time though...
How you account distance danger? I get with Tomcat 0.7 APS when take in account min danger to enemy on path instead of distance on last point. Looks like it can help you.
I took a look at some comparisons vs DrussGT and Diamond. One thing that strikes me is that in a bunch of them, your survival is much lower, and DrussGT/Diamond get very high survival. This could just be a side effect of not being strong vs those bots, but it could also be a deficiency in your bullet power selection. Actually one of my most recent improvements to Diamond was in my bullet power formula.
It definitely seems like there are a bunch of matchups that should give some clues. And I agree distancing is important. I gained a bunch just from changing the shape of the curve I use when factoring distance into my danger calculation.
Alright -- nobody run any more Rumble battles, because I currently have the top score against DrussGT. :-P I still don't know what I did that made me lose about 0.3 APS, but even if I figure it out, I won't be putting up a new version for a little while. I have some new changes I'm working on and I intend to run a gazillion test battles before the next time I release anything, so for awhile I'll be out of the top 10.
I just compared the versions 11.15 and 11.11 with eachother, and the new version is much worse against 'simple' bots. 97% dropping to 88% is very very bad, the other quadrupled its score! My tip: run battles against f.e. Supersample.SuperCorners and watch what is happening. Loosing rounds against such an opponent should not happen and the reason is hopefully easy to see (radarlock, gundirection).
GrubbmGait -- good advice. Definitey something wrong there. There is also one battle against Timbot where XanderCat only scored a 7 APS. I would guess an error slipped through where an exception can occur causing XanderCat to freeze and lose a round occasionally (or in the case of the Timbot instance, get shutdown completely). Whatever it is, it definitely needs to be fixed.
I'm pretty certain I found and fixed the primary bug (there may be an underlying secondary bug to fix, but the exception should be gone). I know I said I wasn't going to release another version pre version 12, but since it is an exception that is occurring, I feel I should go ahead and fix it. So I'm putting out 11.16 today.
I know some of you have said things about this recently, and version 11.7 of XanderCat is a good example. To be at the top, you really have to iron out all the little things to ensure there are not any score losses, even if they seem tiny. Squeeze every last point out of every feature you implement.
In version 11.7 of XanderCat, I updated my anti-mirror components. The new version was better in a lot of ways, and able to detect a wider array of mirroring tricks. However, my overall APS dropped enough to take me from 8th down to 12th place. The reason? More false positives on mirror detection (robots briefly detected as mirroring when it was really just coincidence). My new components, able to detect mirroring in a variety of new ways, amplified the losses from the false positives. Furthermore, it means I might be able to improve further than I had previously if I can completely stamp out of those false positives in a future version.
What other ways could I eliminate minor losses and see noticeable improvements in overall APS? What other ways might you be able to do the same? My next step will be to verify whether or not I'm losing any ground do to wall collisions (based on my latest stats, XanderCat runs into walls on average 43 times on every battle! But ultimately it depends on how much energy I'm losing from it, which I should know in another day).
That's pretty interesting. You can definitely squeeze some points out of rammers, but for me that was more a matter of personal pride / fun than really going for APS. My bullet power, distancing, and kernel density formulas had a surprising amount of room for improvement even after Diamond was at #2
On wall hits, I'm curious how that turns out for you. Dookious and Diamond hit walls sometimes in 1v1. In Melee, Diamond uses precise prediction to never choose a movement option that would hit the wall in the next few ticks, and the result is a really smooth and nice and beautiful Melee wall smoothing that never hits walls but really hugs them. I tried applying this same logic to my 1v1 movement to avoid all wall hits, and it was a super huge pain to get it all working right, and then I gained no points from it. So I removed all the mess and just left it at hitting some walls sometimes.
As a thought on avoiding false positives in mirror detection, I'm pretty happy with the margin of error calculation setup I use in my flattener enablement. Basically, the hit % threshold I use to enable the flattener has a margin of error added to it, so I only enable it if I have 95% confidence that the enemy's "true" hit % is over that threshold. Maybe you could do similar and be really conservative in your detection early on and gradually get more aggressive as the battle goes on and you gather more data. I'm not sure how that will hold up with multi-mode bots but it's definitely something I'd explore.
Sorry to double post, but on the wall hits, consider: if you can slam into the wall at full speed and take a bunch of wall hit damage and it's your best chance to avoid a HOT or linear targeting shot, do you really want to rule it out as an option? Hitting the wall doesn't cost you score unless you lose a round, but taking some bullet damage costs you a lot of % score against such a bot.
Not enough battles to know for sure yet, but looks to me like eliminating hitting the wall will only have a very marginal impact on score. Version 11.8 is currently showing only 0.05 APS better than 11.7.2, despite hitting walls only about 1/3 as often. Oh well. On to the next possible improvement. I'd really like to get a solid lead over Hydra.
Here's an outlier: [1]
XanderCat 11.7.1 scores 57.46 against Druss GT 2.8.5 -- Ironically, ran by Skilgannon so no crying foul play. ;-) Due to a run of luck on the Rumble, PL score for 11.7.1 after 1 battle against each opponent was silly high -- only losses were to Diamond, Tomcat, and WaveSerpent. Maybe I can pull it before it starts dropping. ;-) The change in 11.7.1 looks like it didn't fix what I broke in 11.7. 11.7.2 coming soon...
What's the secret to beating this guy? The better my robot gets, the lower my score against PrairieWolf gets (current PBI is -25 and getting worse). I'm at a point now where I have a lot of trouble getting over 50 APS against PraireWolf, despite there being a lot of much lower ranked robots that seem to have no trouble at all. I've been mucking around with different aspects of my robot to no avail. I guess I have my new nemesis.
PW has a bunch of movement modes so maybe just one of them is giving you trouble? Have you watched some battles?
A long time ago a version of Dookious was losing to PrairieWolf. I eventually watched enough to find that PW's "vibrating" movement mode was confusing the heck out of me - I kept trying to shoot ahead of him, not shooting because my gun wasn't turned all the way, then he'd reverse direction and I'd start aiming the other way. So I'd just never shoot.
PrairieWolf's page says it has Circular Targeting, but it looks like it must have some sort of averaging or randomization. I would suggest using something like active bullet shadowing or rsim style Bullet Shielding, but I realize that's easier said than done.
I would guess it's PrairieWolfs Reflection movement (Mirror Movement), but XanderCat is doing well against other mirror bots.
I'm pretty sure it is not PrairieWolf's mirror movement. I paid special attention to that, and from what I could tell, XanderCat handled that movement without any trouble. From what I can tell so far, it may be a combination of subtle problems. Ultimately my hit ratio is worrisome low, and PrairieWolf's hit ratio against me is worrisome high. The multiple drive modes may be polluting my gun data some, though I have data roll that should help with that. As for why the hit ratio against me is high, that's more of a mystery. PrairieWolf looks to have one of the highest hit ratios against me in the entire rumble (excluding close range fighters, though I am not looking very close at bullet power either).
There are other top bots that have trouble with PrairieWolf, so I'm not alone there (I think FireBird is at about 50 APS against it). But some other top robots beat PrairieWolf by quite a margin, so I know there is lots of room for improvement. For now, I remain a bit stumped. I have a few other changes to push forward with for now, but I will definitely be back to focus on PrairieWolf in the future.
Hey, congrats on 8th place! I think every spot you move up at this point is like another milestone. :-) (I guess 1/2 and 3/4 are pretty close though.) And a belated welcome back...
Thank you! The next rank up is a pretty big step. It will take some magic, but I'll work on it. I was thinking my next step, partially out of curiosity, will be to do a new round in the gun and drive challenges. I'm interested in trying to determine if there is more room for improvement in my guns or my drives, or if they seem pretty balanced at the moment. I've been playing with a lot of parameters, but I think continued effort on improving my segmentation (in both the drives and guns) offers the most promise for further improvement. I don't think I will be beating Diamond any time soon, but with a little more work, perhaps I can at least give you a moment of pause anytime XanderCat comes up in the challenge queue against Diamond. :) - Skotty
Just noticed, that XanderCut get very close to the group challenging the crown:) And congrats with scores against Shadow - i think tens of robocoders dreaming about it:)
Not sure what I broke in version 11.1. I'll be looking into it over the next few days. The changes I made were mostly cleaning up the code, so performance shouldn't have changed much.
Just to close off this thread, the problem with version 11.1 was with the wave cache I created for the 11.x series of robots. Wave creation is far more expensive with Precise MEA turned on in my Xander framework. At the same time, each guess factor gun would create a wave for itself when aiming before any actual wave yet existed. This resulted in pretty much the same wave getting created multiple times, resulting in the same Precise MEA getting predicted multipled times, which was absurdly expensive. The wave cache was meant to help fix the problem by allowing waves to be reused. However, the implementation was a bit flawed, and waves that were not quite identical could get reused. Ultimately, I really only needed to cache the Precise MEAs, so I changed it to an MEA cache instead of a wave cache, which actually simplifies it, and more importantly, fixes the problem.
One last note -- my Precise MEA calculation could be improved, and I may work on it in the future. The current implementation works, but it uses a shotgun brute force approach which I should be able to improve if I put my mind to it. What makes it so tricky is handling situations where the robot is near walls in combination with taking drive limitations into account (turn rate, accel/decel rates).
Not sure how many people follow it, but FYI, I hope you're not too bothered by XanderCat being ommitted from the @roborumble Twitter feed for now. I'm pretty sure it's interpreting your bot name as a URL and failing somehow (they started auto-shortening all URLs recently). Even trying to post the same tweets through the web interface errors out for me. I reported the issue a week or two back but no response yet...
Although I'm not quite sure what you are talking about, as I don't use Twitter, I just tonight fixed the Download link for the JAR on the XanderCat wiki page. It has been broken for a number of weeks (I didn't realize it until today). I just mention it in case that might have had something to do with it. Or maybe that's completely unrelated. I don't know.
You know, I'm not sure how it works, but I use the NoScript add-on in Firefox and it currently blocks code from the Twitter domain twimg.com. Maybe that was causing the issue? I could unblock it.
I'm a couple days late on this, but wow, congrats on entering the top 10! Ascendant was #1 when I started Robocoding, so he is a particularly special milestone for me. =) And you're also beating Shadow over 11 battles. Truly awesome.
You do not have permission to edit this page, for the following reasons:
You can view and copy the source of this page.
Return to Thread:Talk:XanderCat/Top 10/reply.
Congrats indeed! Y'know, at one point RougeDC was bordering at the top-10, but these days the top-10 is much trickier!
About multi-mode robots, what about flatteners? I think all top-10 robots with the lone exception of Scarlet use a flattener, and personally I consider a flattener to be a form of multi-mode technically :P
Tomcat also has no flattener, which can be treated as multi-mode. Tomcat is more continously adapt his behavior to dodging or flattening, than turn on or turn of flattener by some events
I think arguing that a flattener is multi-mode functionality is reasonable, though I think the majority of people would not consider it so. On the flip side, someone could argue that my robot is only marginally multi-mode, despite it various "scenarios", as about 95% of the time it is using the default gun array, and about probably 70% of the time it is using the default wave surfing drive.
Congrats from me to, although I am not so happy that my (flattenerless) robot now is pushed out of the top-10 again. But I must warn you, this triggers the drive to do some real changes instead of tweaking. ;-)
Congrats from me too:)
Looks like i must start worry not only how to get crown, but also how to save third place:)
And are you remember, what i speak about our own TOP-3?:) Chase?:)
Wow, that was worth doing! Finally fixed my flawed bullet shadows implementation I put in place back in version 9. My rank didn't change due to being in a bit of an empty area in the APS distribution, but APS increased by about 0.4, and for the moment, I'm tied for 4th in PL. However, I have a lot of battles that are very close to 50 in % Score; I could see possibly losing my lead against CassiusClay, Shadow, and Scarlet (wee! I've never beat Scarlet before!). Meanwhile, Diamond, Druss, and Tomcat continue to be quite deadly; I'd be happy to make 45% against any of them.
Looks like yours BS implementation still broken or not prefect, because BS must give you about 1 APS (at least DrussGT's, Diamond's and Tomcat's results say so)
Not necessarily. My original buggy implementation was sort of working; it just wasn't working very well. To tell how much difference my new implementation makes (versus not using it), I would need to run a new test with it turned off.
First page |
Previous page |
Next page |
Last page |