User talk:Duyn/BucketKdTree
Performance Discussion
Notice: This discussion was merged from User talk:Duyn/kd-tree Tutorial --Rednaxela 01:32, 3 March 2010 (UTC)
Also, I'd say that the 'Bounds-overlap-ball check' optimization is probably one of the most important things in how this tree benchmarks well. I also find it interesting how that optimization is in that paper, I've never seen it mentioned before in texts on kd-trees. However when I implemented that type of check in my own kd-tree, it just came to mind to do in a "... why hasn't anyone else done this? It seems so obvious" type of moment. You may be interested in one detail of how I was doing it differently though. I didn't use those bounds checking for the path order, I just used the conventional method based on the split. In addition, I only do did the 'bounds-overlap-ball check' for evaluating if 'second choice' branches are worthwhile. The reason for this is that:
- Bounds checks are expensive
- The 'first choice' branch to descend is very likely to have what we're looking for since it's parent branch was either a 'first choice' branch or had the bounds check done on it.
Benchmarks showed that those effect were significant enough that the detailed bounds check was only worthwhile in pruning needless 'second choice' branches. I'm curious if your implementation would show similar results if it skipped the bounds chck in those circumstances. --Rednaxela 01:43, 28 February 2010 (UTC)
Thank you for the suggestion. I have tried it, but found it didn't make a significant impact on the performance of the tree:
...[snip]... RESULT << k-nearest neighbours search with duyn's Bucket kd-tree >> : Average searching time = 0.078 miliseconds : Average worst searching time = 17.077 miliseconds : Average adding time = 2.49 microseconds : Accuracy = 100% ...[snip]... BEST RESULT: - #1 Rednaxela's Bucket kd-tree [0.0536] - #2 duyn's Bucket kd-tree [0.0777] - #3 Simonton's Bucket PR k-d tree [0.1625] - #4 Voidious' Bucket PR k-d tree [0.2203] - #5 Nat's Bucket PR k-d tree [0.3654] - #6 Voidious' Linear search [0.5836] Benchmark running time: 554.32 seconds
Although these results are perilously close to the rounding edge, it works out to a gain on previous performance of:
<math>{0.0787 - 0.0777 \over 0.0787} = 1.27\%\ \mathrm{improvement}</math>
Profiling with netbeans indicates it is the search() and searchXXX() functions, not the distance/bounds calculations which are slowing the tree most. This suggests that:
- the tree's balance is not optimal so we have to search a lot of trees;
- unlikely: quickly hacking in support for re-balancing every time the number of exemplars in a tree doubles did not speed up searches.
- the regions are not very square so our search hypersphere overlaps with a lot of hyperrects;
- unlikely: splitting on the widest dimension whenever it turns out to be twice the width of the thinnest dimension did not speed up searches.
- using a TreeMap for collecting results is slow; or
- this is now confirmed. Results with a custom pairing heap (with special handling for duplicates) show a small but significant improvement in performance:
- #1 duyn's kd-tree 2 [0.0707] [ed: with custom heap and delayed bounds check]
- #2 duyn's Bucket kd-tree [0.0822]
- there is little more to gain without another theoretic insight.
- ie. the algorithm's good, but my coding sucks =).
The small improvement from your suggestion becomes more significant now. I shall have to update the main page to reflect this eventually.—duyn 04:41, 28 February 2010 (UTC)
Ahh yeah. Well, I didn't expect a miraculous improvement, and that is pretty close to the rounding amount. I do seem to remember though from my tests that while the improvement was small it was unambiguous, and I'd expect it to matter increasingly as the tree becomes increasingly deep beyond what this test data does. I doubt the TreeMap is the issue. While I used a max-heap in mine, since it's theoretically fastest and my implementation is very good, I doubt it's used quite enough to be a issue in this case. If you're concerned about that though, perhaps test out replacing it with the max-heap from my tree as a test? About the regions and balance, that's quite possible. Hmm... this reminds me, I really should experiment making a tree with "incremental near neighbor search", which instead of searching for a fixed number of nearest neighbors gives an iterator. Also, I should probably experiment with automatic rebalancing parts by tracking depth since insertion is orders of magnitude faster than searches anyway... --Rednaxela 05:44, 28 February 2010 (UTC)
By the way, if you're curious, the newest version of my tree is faster than the one bundled with the benchmark, which I'm pretty sure you compared to:
RESULT << k-nearest neighbours search with Rednaxela's Bucket kd-tree BENCHMARK BUNDLED VERSION>> : Average searching time = 0.083 miliseconds : Average worst searching time = 1.836 miliseconds : Average adding time = 7.17 microseconds : Accuracy = 100% RESULT << k-nearest neighbours search with Rednaxela's Bucket kd-tree NEWEST VERSION >> : Average searching time = 0.065 miliseconds : Average worst searching time = 1.326 miliseconds : Average adding time = 7.1 microseconds : Accuracy = 100%
--Rednaxela 03:22, 1 March 2010 (UTC)
Form your latest result above, it seems that your k-d tree is lack of accuracy. You'll have to improve that though.
Just a note about the accuracy, the benchmark use the first implementation (as ordered in searchAlgorithms array) to check the accuracy, so make sure that you still have FlatKNNSearch.class as the first implementation. Or if you think this may slow down your benchmark, I believe Rednaxela's k-d tree is stable enough to be use as a reference implementation. And the order of output isn't important for accuracy calculation, it just check it have the same result set. --Nat Pavasant 11:32, 1 March 2010 (UTC)
Thanks for pointing that out. That wasn't obvious from a quick scan of the source code. Accuracy does drop when using the PriorityQueue (probably because of incorrect handling of duplicates), but the intent was just to show that there is a lot to be gained by using a more efficient data structure than a TreeMap to collect the results.—duyn
One note, is with my own tree, I made a modified version that did "BOB" checks for 'first choice' branches and also using those "BOB" calculations on the path ordering like you do. The result? The average search time did not change, but the max search time decreased by 20% which I found interesting. This means there is actually a significant tradeoff happening which could be exploited. I'm now trying to determine an appropriate heuristic to decide if it's worth doing "BOB" on 'first choice' and for path selection. I currently suspect a good heuristic would be to use the somewhat expensive "BOB" checks (including for path selection) only when the total number of points in the tree below the node in question is above a certain count. I'll post results with that soon if you wish. --Rednaxela 15:21, 1 March 2010 (UTC)
- This image shows the only case I can think of when bounds checking on both branches would give a different result from using the split point:
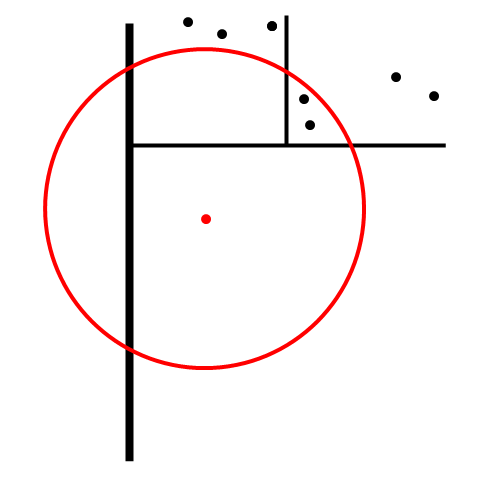
- Judging from the image, it looks like the likelihood of this situation arising increases when sub-trees are sparse or the query point is close to the splitting edge.—duyn 19:41, 1 March 2010 (UTC)
- Agreed, but also, I'm pretty sure that when one gets into 13 dimensions rather than 2, the probability of these circumstances being the cases is much higher. Indeed, I would expect closeness to the splitting edge to matter. I'm currently thinking the best heuristic would be a combination of both 'closeness to splitting edge' and 'number of points contained', because the cost of making the 'mistaken' path is so much greater when one is further from the leaves. I do think right now that the 'number of points contained' is the overriding factor though, due to my result of max search time decreasing while average stays the same. This suggests that the gains mostly happened near the end of the test iteration and had a penalty near the start when the tree is smaller. Can't currently check though since my code is at home and I'm not at home at the moment. --Rednaxela 19:55, 1 March 2010 (UTC)
- Well, after experimenting with both forms of heuristic I've had no luck. It looks like that "20% worse case improvement" I saw just a fluke. Even when averaging over 40 iterations, the 'worst search time' seems to have an awfully high jitter. --Rednaxela 07:11, 2 March 2010 (UTC)
- Agreed, but also, I'm pretty sure that when one gets into 13 dimensions rather than 2, the probability of these circumstances being the cases is much higher. Indeed, I would expect closeness to the splitting edge to matter. I'm currently thinking the best heuristic would be a combination of both 'closeness to splitting edge' and 'number of points contained', because the cost of making the 'mistaken' path is so much greater when one is further from the leaves. I do think right now that the 'number of points contained' is the overriding factor though, due to my result of max search time decreasing while average stays the same. This suggests that the gains mostly happened near the end of the test iteration and had a penalty near the start when the tree is smaller. Can't currently check though since my code is at home and I'm not at home at the moment. --Rednaxela 19:55, 1 March 2010 (UTC)

I might have to try benchmarking mine, but have not done much java lately. --Chase 16:36, 1 March 2010 (UTC)
- I just tried fitting your tree into the benchmark framework, however it doesn't implement the type of search the benchmark is testing: nearest-n-neighbors. Your tree currently only implements nearest-1-neighbor and some range searches. I may later today quickly add a nearest-n-neighbor search to your tree though, since it is very little different than a range search. --Rednaxela 17:49, 1 March 2010 (UTC)
- Actually I am currently rewriting a bit of it, there is a great deal of useless junk in the one I currently have up. Not having a nearest n neighbor routine is a little unforgivable as well. I just have to be sure to test it first. :) --Chase 18:58, 1 March 2010 (UTC)
- Hmm, actually your range search is different than I thought, so it can't be easily adapted to nearest-n-neighbors. Normally "range search" in kd-trees means searching for points within a certain hypersphere, not hyperrect. Best of luck with the rewriting :) --Rednaxela 19:16, 1 March 2010 (UTC)
- Yeah, this is the 'true' KD-Tree range search as defined by multi-dimensional and metric data structures. As for the rewrite, I am almost done, I wrote a handmade PriorityDeque for use with it, it is a generic class so others might find use of it later. Adding in the nearest N neighbors now will be very simple. I haven't spent all my time away slacking off (has been doing C++ and assembly). --Chase 21:01, 1 March 2010 (UTC)
- Alright, finished, you can give it a try now. I tested it and it seems to match the linear search's output in my inhouse tests, but I did not test the range search this time around, so that might still be buggy. Feel free to use the PriorityDeque if it strikes your fancy.. --Chase 21:41, 1 March 2010 (UTC)
- Hmm, actually your range search is different than I thought, so it can't be easily adapted to nearest-n-neighbors. Normally "range search" in kd-trees means searching for points within a certain hypersphere, not hyperrect. Best of luck with the rewriting :) --Rednaxela 19:16, 1 March 2010 (UTC)
- Actually I am currently rewriting a bit of it, there is a great deal of useless junk in the one I currently have up. Not having a nearest n neighbor routine is a little unforgivable as well. I just have to be sure to test it first. :) --Chase 18:58, 1 March 2010 (UTC)
Out of curiosity Duyn, I adapted a version of your tree to use my ResultHeap and here is the result:
RESULT << k-nearest neighbours search with Rednaxela's Bucket kd-tree (Sept 5, 2009) >> : Average searching time = 0.054 miliseconds : Average worst searching time = 22.13 miliseconds : Average adding time = 4.13 microseconds : Accuracy = 100% RESULT << k-nearest neighbours search with duyn's Bucket kd-tree >> : Average searching time = 0.116 miliseconds : Average worst searching time = 36.604 miliseconds : Average adding time = 5.14 microseconds : Accuracy = 100% RESULT << k-nearest neighbours search with duyn's Bucket kd-tree (using Rednaxela's ResultHeap) >> : Average searching time = 0.075 miliseconds : Average worst searching time = 33.756 miliseconds : Average adding time = 5.18 microseconds : Accuracy = 100% BEST RESULT: - #1 Rednaxela's Bucket kd-tree (Sept 5, 2009) [0.0538] - #2 duyn's Bucket kd-tree (using Rednaxela's ResultHeap) [0.0752] - #3 duyn's Bucket kd-tree [0.1165]
I'm also suspecting that the results as low as you saw with PriorityQueue showed unusually low accuracy even were it to treat duplicates differently I think. I suspect that PriorityQueue version had some other bug causing it to skip parts of the search and thus appear faster than it should. --Rednaxela 22:38, 1 March 2010 (UTC)
- You are right, I made the silly mistake of ordering the comparisons the wrong way in my initial hack, assuming a priority queue would return the item with the highest priority. The results after fixing this (and a few other changes I can't be bothered backing out for a fair comparison):
RESULT << k-nearest neighbours search with duyn's Bucket kd-tree >> : Average searching time = 0.081 miliseconds : Average worst searching time = 20.569 miliseconds : Average adding time = 2.49 microseconds : Accuracy = 100% RESULT << k-nearest neighbours search with Rednaxela's Bucket kd-tree >> : Average searching time = 0.053 miliseconds : Average worst searching time = 0.507 miliseconds : Average adding time = 1.7 microseconds : Accuracy = 100% RESULT << k-nearest neighbours search with duyn's kd-tree (PriorityQueue) >> : Average searching time = 0.527 miliseconds : Average worst searching time = 437.192 miliseconds : Average adding time = 3.09 microseconds : Accuracy = 100% BEST RESULT: - #1 Rednaxela's Bucket kd-tree [0.0534] - #2 duyn's Bucket kd-tree [0.0807] - #3 duyn's kd-tree (PriorityQueue) [0.5269]
- It is interesting that the PriorityQueue performs so poorly when it implements basically the same algorithm as your ResultsHeap (an implicit binary heap, if I understand both correctly). For anyone else who's interested, this external image shows why: internally storing elements as an Object[] array without separately storing keys necessitates Object-to-Object comparison, which requires slow casting before the real compare() call can be made. The Object-taking method is one of the hot spots in profiling.—duyn 12:40, 8 March 2010 (UTC)
{kind=link}
I was just starting on rewriting my tree to be cleaner, and hopefully just as fast, when I was inspired by the way you put alternate paths in a stack like you do. The thought is, since we both always do a "BOB" check on the alternate paths, and there's a chance that when near splitting edges, the alternate path closer to the root of the tree may on rare occasion be preferable to test before the alternate paths further from the root. Since those paths always have a full "BOB" check distance calculated at some point or another, why not reuse that distance calculation to prioritize the order of checking of alternate branches to be more efficient than 'ordinary' paths to transverse a Kd-Tree? So in my rewritten tree, I'm storing the list of alternate paths in a heap, which makes it very fast to see what the smallest distance alternate path is. I may change from a heap to a plain sorted list or another data structure though, since I'd expect the order-of-insertion should be near-sorted already, making the binary heap perhaps not the fastest data structure for the purpose. Either way, I expect possible gains from this... --Rednaxela 17:52, 2 March 2010 (UTC)
By the way Duyn, out of curiosity I tested your version of the distance functions in my tree, and it made it over 10% slower. I think your distance function optimization might be a spot to work on if you feel like optimizing further :) --Rednaxela 07:33, 4 March 2010 (UTC)
- That's odd. My distance functions are very close to the ones in your SqEuclid class.
- - In
distanceSqFrom, I check for 0 where you check for NaN. - - In
minDistanceSqFrom, I cache the value of the co-ordinates rather than accessing the array each time (which is more for convenience than speed). - It is not immediately clear what in that code could be causing such a speed diference.—duyn 08:28, 4 March 2010 (UTC)
I currently suspect it's due to the minDistanceSqFrom() because the distanceSqFrom is so similar. I think the slightly more complex code path in yours is trickier for the JIT to optimize despite the fact that it would probably be faster in C, I think. Optimizing Java is a bit different from optimizing C. --Rednaxela 22:14, 4 March 2010 (UTC)`
- [View source↑]
- [History↑]
You cannot post new threads to this discussion page because it has been protected from new threads, or you do not currently have permission to edit.