Difference between revisions of "Talk:XanderCat"
(→Which Waves to Surf: comments) |
m (→End of the Road?: removed) |
||
| (132 intermediate revisions by 10 users not shown) | |||
| Line 2: | Line 2: | ||
: Thanks GrubbmGait, though I'm not sure how much praise I deserve for being officially average. :-P I'm trying out a slightly revised version today, version 2.1. No major component changes, but it modifies the bullet firing parameters, driving parameters, some segmentation parameters, and has improved gun selection. [[User:Skotty|Skotty]] 20:43, 25 May 2011 (UTC) | : Thanks GrubbmGait, though I'm not sure how much praise I deserve for being officially average. :-P I'm trying out a slightly revised version today, version 2.1. No major component changes, but it modifies the bullet firing parameters, driving parameters, some segmentation parameters, and has improved gun selection. [[User:Skotty|Skotty]] 20:43, 25 May 2011 (UTC) | ||
| − | == | + | == Rethink / XanderCat 4.8+ == |
| + | |||
| + | I lost some ranks when I refactored the guess factor and wave surfing code in version 4.7, and have yet to get them back. But I'm still convinced the refactor was a good thing. | ||
| + | |||
| + | I've ironed out all the major bugs, and if I watch XanderCat in some battles, I don't see it doing anything obviously wrong. This got me thinking about how I handle segmentation again. I think my philosophy on balancing segments for comparison was wrong in the drive, and am changing it in version 4.8. I also plan on excluding certain segment combinations that when I think about them, just don't make much sense (like using just opponent velocity). I think this should improve performance. | ||
| + | |||
| + | Beyond this, I'm not sure what I would do next to try to improve. I could run zillions of combinations of segments and parameters just to see what seems to work better against a large groups of robots that I think is representative of the whole. Not sure I will go to that extent though. [[User:Skotty|Skotty]] 01:09, 22 June 2011 (UTC) | ||
| + | |||
| + | I'd definitely say that you still have non-negligible bugs / issues with your surfing. Looking at [[Barracuda]] and [[HawkOnFire]] again, compared to [[DrussGT]] we have 95.82 vs 99.83 and 97.91 vs 99.91. In other words, both are hitting you ~20x as much, totally unrelated to how you log/interpret stats (because they're HOT). Not to be a downer - XanderCat is coming along great and you appear to have a really robust code base. Or if you're burning out on 1v1, how about Melee? It's a much different animal. =) --[[User:Voidious|Voidious]] 01:28, 22 June 2011 (UTC) | ||
| + | |||
| + | :It appears as though I'm on the right track with version 4.8. Just for you Voidious (grin), in addition to other changes, I configured it to maximize scores against head-on targeters, which raised the [[Barracuda]] and [[HawkOnFire]] scores to 98.98 and 98.76 respectively (2 battles each so far). To get the rest of the way to [[DrussGT]] levels, I will need to tweak my dive protection a little more; it still causes XanderCat to stall near a wall long enough to be hit every once and awhile. I may need to also tweak my "Ideal Position Drive" a bit more too, as it still drives too close to opponents occasionally when trying to reach an ideal position (the Ideal Position Drive drive runs at the start of each round before bullets start flying). | ||
| + | |||
| + | : Nice. =) For better or worse, the RoboRumble greatly rewards bots that can annihilate HOT and other simple targeters, so you might be surprised by how much of a ranking increase you can find by polishing that aspect of your surfing. It's not always the sexiest thing to work on, nor the most fun... But more importantly (to me), it's just a good way to verify that your surfing is working how it should. I can't find a good quote, but both [[User:Skilgannon|Skilgannon]] and [[User:Axe|Axe]] have commented on the fact that if even a single HOT shot hits you, there's something wrong. --[[User:Voidious|Voidious]] 17:51, 22 June 2011 (UTC) | ||
| + | :: Very true. A wavesurfing bot should be able to dodge all *known* bullets perfectly, and HOT is only known bullets. Unless there is something funky like bullets fired from 20 pixels away, or a gun cooling time of 1 tick, all bullets *should* be avoidable.--[[User:Skilgannon|Skilgannon]] 11:54, 23 June 2011 (UTC) | ||
| + | |||
| + | : Nice work, but just as a note, some might think me crazy, but I don't think *any* explicit dive protection is necessary for this sort of thing really. My surfing bots RougeDC and Midboss (same movement code), get 99.5% against HawkOnFire with no explicit dive protection whatsoever (and in certain past versions they did even better IIRC). The thing is, as I see it, dive protection is completely unnecessary if the surfing properly considers how movement changes botwidth. I much prefer it that way as it doesn't require tweaking/tuning to get right. Just my 2 cents on dive protection. --[[User:Rednaxela|Rednaxela]] 20:50, 22 June 2011 (UTC) | ||
| + | |||
| + | :: Well, I'd still call it "dive protection". =) But yes, I agree that multiplying danger by bot width (or dividing by distance, which I think is still what I do) is about the most elegant solution. And I doubt anyone's calling you crazy. Do any top bots since [[Phoenix]] use special cases? I guess I'm not sure about [[GresSuffurd]] or [[WaveSerpent]]. --[[User:Voidious|Voidious]] 21:14, 22 June 2011 (UTC) | ||
| + | |||
| + | ::: Oops, I guess I'm out of touch. [[Diamond]] still has special cases, despite taking this approach - it scales the danger more than linearly beyond a certain threshold, as [[Dookious]] did. Maybe I'll test removing that, just for the sake of argument. =) I think it will lose points, though. Sure, for one bullet, the danger scales linearly with bot width. But that bot width affects future waves too. I suppose whether this is "explicit dive protection" would be up for debate. --[[User:Voidious|Voidious]] 21:24, 22 June 2011 (UTC) | ||
| + | ::::Hmm...considering my own robot width when surfing...why didn't I think of that before? Guess what new feature will be in version 5.0? :-D [[User:Skotty|Skotty]] 22:44, 22 June 2011 (UTC) | ||
| + | ::: Rather than multiplying danger by bot width, I prefer integrating over the affected bins, since many bins can be covered at close range... ;) --[[User:Rednaxela|Rednaxela]] 22:49, 22 June 2011 (UTC) | ||
| + | ::: [[GresSuffurd]] has 2 lines of code handling both distancing and dive protection. This code hasn't been changed for years. The dive protection just handles the angle, not the danger. My latest effort was to use the summed danger of all covered bins instead of the danger of one bin to decide which direction to go(forward, stop, backward), but this approach let me fall out of the top-10 ;-) Sometimes a simple, proven, not optimal solution works better than a theoretical optimal solution. I do like the idea of letting danger instead of angle decide when to change direction though, and I will continue in this path with the next versions. Welcome to the dark caves of Robocode. --[[User:GrubbmGait|GrubbmGait]] 23:25, 22 June 2011 (UTC) | ||
| + | :::: If it's ever pitch black, watch out for GrubbmGait's pet Grue ;) --[[User:Rednaxela|Rednaxela]] 00:21, 23 June 2011 (UTC) | ||
| + | :::: I think the reason these approximations often work better is that we're using a discrete system, and often the optimal assumes continuous. I think the other reason is that the optimal system often gets horrendously complex and bugs creep in, making the simple system actually more accurate. But these are just thoughts =) --[[User:Skilgannon|Skilgannon]] 11:54, 23 June 2011 (UTC) | ||
| + | ::::: Well, in this specific case, I would say the "optimal system" doesn't get more complex. I would argue integrating over botwidth is less complex, because: | ||
| + | :::::# It also implicitly does the most important part of what many people use bin smoothing for | ||
| + | :::::# There aren't really any parameters to need to tune | ||
| + | ::::: To be clear, a very very very tiny amount of bin smoothing is still useful, to cause it to get as far as possible from danger, but the integrating over botwidth really does the important part of the smoothing. Actually, I suspect that if people get lower scores with integrating over bins, it's because it overlaps with their existing smoothing which has become far too strong. | ||
| + | ::::: Basically, sometimes the "optimal system" may actually be less complex. It can reduce how many tunable parameters are needed, and also replace multiple system components necessary to fill a purpose. --[[User:Rednaxela|Rednaxela]] 13:37, 23 June 2011 (UTC) | ||
| + | :::: I also think we tune around a lot of arbitrary stuff in our bots. I remember [[User:PEZ|PEZ]] and I often lamented how something we'd set intuitively, and "couldn't ''possibly'' be optimally tuned!", resisted all attempts to tune it. I imagine that's sometimes the case when an existing simple/approximate approach performs better than the "new hotness totally scientifically accurate" approach. Dark caves indeed. =) --[[User:Voidious|Voidious]] 14:48, 23 June 2011 (UTC) | ||
| + | :::: For the record, I don't use binsmoothing, as I don't see the purpose of it. If a safe spot is near danger or far away from danger does not matter, it is still a safe spot. --[[User:GrubbmGait|GrubbmGait]] 19:16, 23 June 2011 (UTC) | ||
| + | |||
| + | == Case Analysis == | ||
| + | |||
| + | Just out of curiousity, does anyone have any insight as to why deo.FlowerBot 1.0 drives so predictably against gh.GresSuffurd? I can't figure it out. FlowerBot just drives around in a big circle when fighting GresSuffurd, while seeming far less predictable against XanderCat 4.8. Maybe it's a distance thing? Looking a little closer, I see that a lot of top robots are only getting about 70% against FlowerBot, so perhaps it's just a lucky tuning on the GresSuffurd matchup (or unlucky, in the case of FlowerBot). | ||
| + | |||
| + | I'm hunting around to find cases where XanderCat performs poorly in cases where top robots perform very well. So far I haven't found a case I can learn anything from. I'll keep looking... | ||
| + | |||
| + | Flowerbot has a bug. This bot is derived from the (original) BasicGFSurfer which had a flaw when bullets had a power of x.x5 It could not match the bullet to a wave due to a bug in the rounding, therefor it did not 'count' the hit as a hit in its surfing. Just try out and always fire 1.95 power bullets at it, you will obliterate it. There are still some more bots using this codebase, so this 'bug-exloiting' could gain some points for you. --[[User:GrubbmGait|GrubbmGait]] 19:25, 23 June 2011 (UTC) | ||
| + | |||
| + | :Yep. That's it. [[User:Skotty|Skotty]] 19:35, 23 June 2011 (UTC) | ||
| + | |||
| + | == Which Waves to Surf == | ||
| + | |||
| + | Anyone tried surfing all enemy waves at the same time? XanderCat currently surfs the next wave to hit, but I've been thinking about trying to surf all enemy waves simultaneously. Not sure if it would be worth trying or not. | ||
| + | |||
| + | Yep, many modern bots do. I surf two waves and weight the dangers accordingly. Doing more or all waves (would be just a variable change) would have almost no effect on behavior, because 3rd wave would be weighted so low, but cost a lot of CPU. --[[User:Voidious|Voidious]] 19:45, 23 June 2011 (UTC) | ||
| + | |||
| + | In addition to what Voidious says, I'd like to note that going beyond two waves without eating boatloads of CPU could perhaps be done if one tries to be creative. One option is doing something like two and a half waves. What I mean by "half" is for the third wave, taking an approximate measure such as "If waves 1 and 2 are reacted to in this way, what is the lowest danger left for wave 3 that is approximately possibly reachable?". That approach leaves the branching factor of the surfing equal to 2-wave, but allows the 3rd wave to break ties in a meaningful way. Now... I haven't actually tried this, but just a thought about how to go beyond 2 without eating too much cpu. It might help in cases where the reaction to the first two waves would normally leave it particularly trapped... --[[User:Rednaxela|Rednaxela]] 21:16, 23 June 2011 (UTC) | ||
| + | |||
| + | :I'm trying out surfing 2 waves at once for version 5.0, but I'm not sure how well it will work. I'm currently weighting the danger of the closer wave at 80%, and the 2nd wave (if there is one) at 20%. This is more a gut feeling for now. I may have to change it later. On a related note, version 5.0 pays more attention to robot width, such as determining when enemy bullet waves hit and when they are fully passed, but I was torn as to when to stop surfing the closest wave. Do I continue to surf it until it is fully passed, or do I stop surfing it right when it hits to try to get an earlier start on the next wave? For now, I'm doing the latter. [[User:Skotty|Skotty]] 13:15, 24 June 2011 (UTC) | ||
| + | |||
| + | :: About weighting between the waves, I believe one popular approach is weighting by (WaveDamage+EnergyGainOpponantWouldGet)/(distanceWaveHasLeftToTravel/WaveSpeed). This approach is nice because it gives a reasonable weighting of waves in "[[oldwiki:ChaseBullets|ChaseBullet]]" scenarios. | ||
| + | :: As far when to stop surfing a wave... what I personally do, is surf the wave until it has fully passed, BUT I reduce the danger to 0 for the exact range of angles that would have already hit me (this is all using [[Waves/Precise Intersection|Precise Intersection]] to determine what range of angles would hit for each tick). This means that a wave that has almost completely passed me, will still be getting surfed, but care about those few angles that could still possibly hit (meaning, very low weight often). --[[User:Rednaxela|Rednaxela]] 16:47, 24 June 2011 (UTC) | ||
| + | :: Yeah, (damage / time to impact) is good, maybe squared. I can't remember if XanderCat is reconsidering things each tick (ie, [[Wave Surfing/True Surfing|True Surfing]]) or not, where that formula makes sense. While Rednaxela's setup is by far the sexiest, in a less rocket sciencey system (such as [[Komarious]]), I definitely favor surfing the next wave sooner - like once the bullet's effective position* has passed my center. (*Dark caves note: in [[Robocode/Game Physics|Robocode physics]], a bullet will advance and check for collisions before a bot moves. So for surfing, I add an extra bulletVelocity in cases like this.) --[[User:Voidious|Voidious]] 17:53, 24 June 2011 (UTC) | ||
| + | :::Originally, XanderCat was reconsidering things each tick, but I was running into what I referred to as "flip flopper" problems, where XanderCat would keep changing it's mind, and it seemed to be hurting performance. So I switched it to only decide where to go when a new bullet wave enters or leaves the picture (plus it processes less that way). However, I could see reconsidering every tick as being superior with the kinks worked out, and the "go to" style surfing has problems with dive protection. I therefore just modified my drive again to make the frequency of surfing configurable -- a hybrid approach between "go to" surfing and true surfing -- where I can set the max time to elapse before a reconsideration is performed; if the waves in play haven't changed before the time limit elapses, a reconsideration is executed. This becomes true surfing when you drop the time limit to 1. Not sure what value I will use for 5.1+ yet. [[User:Skotty|Skotty]] 19:59, 24 June 2011 (UTC) | ||
| + | |||
| + | == Rolling Average == | ||
| + | |||
| + | I notice you say you are using a very high rolling average in both movement and gun. I have found in [[DrussGT]] that the gun should have a very high rolling average, but the movement a very low one to deal with bots that have adaptive targeting. By low I mean less than 5 on very coarsly segmented buffers, and less than 1 on finely segmented buffers. But I suggest you experiment with your own data and figure out what works best for you =) --[[User:Skilgannon|Skilgannon]] 10:35, 27 June 2011 (UTC) | ||
| + | |||
| + | == #1 Against PolishedRuby == | ||
| + | |||
| + | I just checked for fun, and found that XanderCat currently holds the #1 score against [[PolishedRuby]]! Only 2 battles in the rumble, and only best by a slim margin, so XanderCat could slip down. But for the moment, I would like to claim my virtual gold medal against mirror bots. :-D | ||
| + | {{Unsigned|Skotty}} | ||
| + | |||
| + | Well, seems you certainly have a good anti-mirror system in place. I've never gotten around to building one of those... --[[User:Rednaxela|Rednaxela]] 06:18, 1 July 2011 (UTC) | ||
| + | |||
| + | == Fixing My Wave Surfing Rolling Depth == | ||
| + | |||
| + | I think it is time for me to go back and really think about how I am processing segments to get a low rolling depth working properly on XanderCat. Let me start by giving a quick explanation of how I store my data, as it may be a bit different than what most robots do. | ||
| + | |||
| + | First off, I currently record two types of information. ''Hits'' and ''visits''. ''Hits'' are recorded in a factor array using bin smoothing similar to what BasicGFSurfer does, and ''visits'' is just an incremented integer that says I was at a particular segment combination for a bullet wave, which I do for all bullet waves. | ||
| + | |||
| + | I store all of my wave surfing hit data in a 2-dimension array. The first dimension is the segment, the second dimension is the factors/bins. I can use any number of different segmenters. How this works is that I index all segmenters into the single segment array. So lets say I have segmenter A with 4 segments, and segmenter B with 3 segments, and 87 bins. My hit data array would then be a double[12][87] (3*4=12 segment combinations, 87 bins). | ||
| − | + | I store all of my wave surfing visit data in a 1-dimension array of int. Following in the former example, it would be an int[12] array. At present, this is used to balance the arrays when picking the best one (by dividing by total visits) and to decide whether or not I will consider using a particular segment combination. (e.g., I can say not to use a particular segment combo until it has seen at least X number of visits). | |
| − | + | When I want to consider a particular segment combination to use for surfing any particular wave, I pull back all the indexes that match that segment combination and add the bin arrays for those indexes into a single combined array. | |
| − | + | When I added ''rolling depth'' support, I was only thinking of rolling off hits. I created a List<List<Parms>> for this, where ''Parms'' was just a little class that holded the necessary information to roll back a previously added hit. The outer list index matched the segment index, while the inner list stored data for X number of hits. Once the list reached the preset rolling depth value, for every new hit it would remove the oldest hit from the list and roll it back. So, for example, lets say I get hit, and the combined segment index is 5, factor 23. This would get added to the hit data array (lets call this ''hitArray'') centered at hitArray[5][23]. The hit would also get recorded in the rolling depth list (lets call this ''rollData'') at rollData.get(5).add(new HitParms(...)). If the roll depth had been exceeded, it will then remove the oldest hit data in the list (rollData.get(5).remove(0)) and roll the old hit off the hitArray (same as adding a new hit, only it uses the saved data and applies a negative hit weight to remove the old hit). | |
| − | + | To complicate things a tad further, I also add what I call a ''base load'' to whatever array is to be used for the current surf wave (this base load doesn't actually get added to the hitArray, it is added to a temporary array used for surfing the current wave). This base load is just the equivalent of a single head-on hit. It gets lost in the background when there is a lot of hit data, but is crucial in the beginning to avoid getting hit by head-on targeting. | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | And finally, I also store a combined no-segment array seperately, which I rely on early in the match when the segment combinations do not have a visit count over a certain threshold. I could obtain this by adding all segment arrays, but this seemed excessive, so I just store it in a separate array. | |
| − | + | Given all this, I'm left wondering a few things. One, what do the rest of you really mean when you talk about having a rolling depth of 1 or 2. Are we talking rolling for every visit, every hit, or something else? Two, how should I handle avoiding head-on early in the battle when there is no data to rely upon without it messing up trying to use a low rolling depth (and will my current ''base load'' approach suffice for this)? Three, as I currently have it implemented, I can only roll hit data for all segments combined. I might could manually roll on the fly in the temporary array used for surfing, but I need to figure out what the rest of you are really talking about when you refer to rolling depth before I try such a thing. | |
| − | + | {{Unsigned|Skotty}} | |
| − | + | Well, the usual "rolling average" method used in most targeting is far far simpler than what you describe. Usually [[wikipedia:Moving average#Exponential_moving_average|exponential moving average]] is used. Instead of decrementing old hits, you just decay the weighting of old data. In a system like you describe with "hits" and "visits" kept separate, the exponential rolling average strategy would be, when you get a hit in a segment: | |
| + | # First, multiply all values in "hits" and "visits" by a constant between 0.0 and 1.0. | ||
| + | # Then add your new hit and new visit, but multiply each by 1 minus the constant. | ||
| + | For an example, if you choose a constant of 0.5, then it means that with there is a hit in the segment, the old data will be worth half as much as before. Also, some bots do it slightly differently so the decay is constant, rather than only occurring when a segment is hit, though that takes a little more work to do efficiently. | ||
| + | The method you describe should work too, if you decrement ''both'' visits and hits when decrementing old hits I believe. I'm pretty sure decrementing both would be necessary to keep the values sane. Personally, I don't consider it worth the complexity, but diverse techniques is always interesting. :) | ||
| − | + | About the "base load", I'm pretty sure most bots do either of the following two things: | |
| + | * Initialize the data to contain the "base load" (which means that in an exponential moving average system, it'll decay away to near-nothing pretty fast) | ||
| + | * or, make the "base load" a special case that only applies when there are no hits in the segment. | ||
| − | + | Hope that helps. --[[User:Rednaxela|Rednaxela]] 23:56, 6 July 2011 (UTC) | |
| − | * | + | Ok, a few things to tackle here. =) |
| − | + | * What most [[Visit Count Stats|VCS]] / [[GuessFactors|GF]] bots do is for each bin, the danger value is a number between 0 and 1. When data is logged for a segment, the value for each bin in that segment becomes <code>((rolling depth * old value) + new value) / (rolling depth + 1)</code>. The "new value" would be 1 for the hitting bin, some bin smoothed value < 1 for the rest. You might use <code>min(rolling depth, times his segment has been used)</code> instead of rolling depth, a trick I learned from [[User:PEZ|PEZ]] - ie, use the straight average if you don't have rolling depth's worth of data. A rolling average of 1 means all previous data is weighted exactly equal to the new data. There's no magical reason you need to use this style of rolling average, but it's pretty simple and elegant. Bots that don't use segments have to come up with different styles of data decay. | |
| − | + | * What you're referring to as a "visit" isn't what most of us are referring to. Generally, a visit is to a ''bin'', not (just) a segment. A visit means "I was at a GuessFactor when the wave crossed me", as opposed to "I was at a GuessFactor when a bullet hit me". A visit is what a gun or a flattener uses to learn. What you're referring to as a "visit" is what you'd use in the min(rolling depth, x) example above, I think. | |
| + | * About hard coding some HOT avoidance... Many bots use multiple buffers at once and sum the dangers from all buffers. In that case, you can just have one unsegmented array and load it with one shot at GF=0 instead of looping through every segment of all buffers. There are other benefits to summing multiple buffers of varying complexities, like having a balance between fast and deep learning (without having to figure out when to switch). In [[Komarious]], I just add a tiny amount of danger smoothed from GF=0 ''after'' I poll my stats - mainly a [[Code Size]]-inspired trick, but not a bad approach. [[Diamond]] just uses a smoothed GF=0 danger when he has no data - this is only until the first time he's hit since he uses [[Dynamic Clustering]]. | ||
| − | + | Hope that helps! --[[User:Voidious|Voidious]] 01:41, 7 July 2011 (UTC) | |
| − | + | : And just a quick note to be clear, the "((rolling depth * old value) + new value) / (rolling depth + 1)" formula that Voidious cites is exactly mathematically equivalent to the method I was going on about above. It's just that the constant I used in my explanation is equal to "(rolling depth / (rolling depth + 1))". Two different ways of describing the exact same thing. Personally, I find what people sometimes term the "rolling depth" number less intuitive than the "what to multiply the old data by" constant, but it's really a [[wikipedia:Tau (mathematics)|matter of personal taste]]. I just through I'd point the equivalence out. :P --[[User:Rednaxela|Rednaxela]] 02:07, 7 July 2011 (UTC) | |
| − | + | What Voidious describes is exactly what I used to do - keep a whole bunch of buffers, where the bins represent the hit probability at that guessfactor, and when logging a new hit use a <code>1/((i-index)*(i-index) + 1)</code> binsmoothing technique coupled with that rolling average formula he gave. There were 2 main problems: execution time (slow), and memory usage (high). I did what I could to get around this by hoisting the inverse of all the divisions outside of the loops and switching to floats, but that only helped so much. So, a while ago I changed my data-logging in DrussGT: instead of a whole bunch of arrays of smoothed hits - with around 100 bins - I instead now keep the guess factor of the last <code>2*rollingDepth + 1</code> hits. Each hit I weight less and less exponentially, by logging each hit into the bin it corresponds to (this is at wavesurfing time), and incrementing that bin with a value that gets progressively smaller. The factor I use for making the increment get smaller is <code>roll = 1 - 1 / (sb.rollingDepth + 1)</code>, and each time I go through the loop I make the increment smaller by doing <code>increment *= roll</code>. By carefully choosing a starting value for <code>increment</code> I was able to make this system perform identically to the one that used the rolling average formula above while using a fraction of the CPU to log hits and a fraction of the memory to store them. Once all the hits are logged into their bin, I take this array of unsmoothed hits and smooth them. This has the huge advantage of taking any duplication of hits and essentially merging them again, speeding up the process further. Bins that don't have hits in them don't need to be smoothed, and in practice there are quite a lot of bins that are empty. Data logging has been sped up because instead of smoothing data into hundreds of buffers, each with a hundred bins, instead I just shift the hits over by one in these hundreds of buffers and add the new hit to the beginning. There are a few other tricks that I used to speed up the whole process, like only allocating the array for the hits once that segment has been hit and pre-calculating the indexes for all the buffers I need to access. But choosing this system has essentially eliminated all the skipped turns DrussGT used to experience, while still keeping all of my hundreds of buffers and all of my original tuning intact. --[[User:Skilgannon|Skilgannon]] 09:23, 7 July 2011 (UTC) | |
| − | : | + | : That's an interesting approach. It seems to me though, that once you're storing a list of hits, why not forgo bins entirely? It seems like it would be simpler and have essentially the same result. Maybe I'm wrong, but I'd think performance could also be improved further, with a method that instead of adding many sets of bins, concatenates a list of the <code>2*rollingDepth + 1</code> hits from each segment, along with the weighting for each list entry. Then instead of calculating the value for a bunch of guessfactor bins, take advantage of knowing the integral of the smoothing function to do a fast and precise calculation of where the peak would be. Just a little thought. --[[User:Rednaxela|Rednaxela]] 12:37, 7 July 2011 (UTC) |
| + | : I've toyed with the idea of using some sort of DC system as a replacement, but the lack of rolling data makes me very hesitant. Also, it's not enough just having one peak (maybe you were thinking of targeting?): I need the danger at every point on the wave. I could use the raw data at each point I need to check, which would be slow, or I can take a whole bunch of evenly spaced samples, which is basically bins, which is what I am doing. My explanation was a bit complex I think. Perhaps a simpler explanation would be: when logging a hit, instead of smoothing the hit into a buffer, put it into a que (of which many exist, at their own 'location' just like a segmented VCS system) and delete the oldest entry in the que. When the time comes to stick the hits into a wave, go through the que and increment the bin in your 'wavebuffer' that corresponds with the GF of each hit in each que. Make sure that the older items in the ques are weighted exponentially lower. When you've put all the hits into that buffer, use a smoothing algorithm to, essentially, 'fill in the blank areas'. That's basically it, the rest is just implementation details.--[[User:Skilgannon|Skilgannon]] 13:42, 7 July 2011 (UTC) | ||
| + | : By forgoing bins I never meant using DC. I mean segmented queues of hits like you have, but use non-bin methods to sum the data and find the peak. When not using bins for storage, I kind of feel it's a silly/wasteful to use bins for analysis of the stored data. As a note, I think DrussGT's movement may be the first actual implementation that fits the segmented log-based guessfactor category. See this chart I made a while back: [[File:Targeting_chart1.png]] | ||
| + | : --[[User:Rednaxela|Rednaxela]] 14:01, 7 July 2011 (UTC) | ||
| + | :: I think [[WaveSerpent]] might fit that too. (Maybe just WaveSerpent 1.x.) And, even further off-topic, I think [[ScruchiPu]] and/or [[TheBrainPi]] might belong in one of those black NN slots - for some reason I thought I recalled them being fed the tick by tick movements, not the firing angle / GF. --[[User:Voidious|Voidious]] 15:59, 7 July 2011 (UTC) | ||
| + | ::: I think [[ScruchiPu]] and/or [[TheBrainPi]] are off this chart entirely. IIRC they are fed by tick by tick movements yeah, but that's neither log-based or visit-count-stat based, so it wouldn't fit in the black slots. It would go in it's own column. As subtype of "play-it-forward" but not a subtype of "2-dimensional log-based". --[[User:Rednaxela|Rednaxela]] 16:32, 7 July 2011 (UTC) | ||
| + | : Off-topic, but... Decaying surf data in a DC system is kinda interesting. Designing a system for it in Diamond really made me appreciate VCS / rolling average. =) Instead of weighting things by age, I sort my "cluster" inverse-chronologically and weight each hit according to its sort position. I actually tried hard to figure out how to emulate a rolling average of 0.7 - the most recent data is weighted about 60/40 to the rest of the data, 2nd most recent is 60/40 to the rest of the rest, etc. That got me thinking about the golden mean, like in [http://www.charlesgilchrist.com/SGEO/PhiRatio/GoldenMean-03.jpg this image]. I weight the most recent scan 1, and the rest by (1 / (base ^ sort position)), with a base of golden mean = ~1.618. So it's 1, .38, .24, .15. I figured the golden mean was cool and magical and this modeled rolling average = 0.7 pretty well, so I stuck with it. =P The first one basically gets a sort position of 0 instead of 1. | ||
| + | : Come to think of it, I really could model it to just weight it exactly how a rolling average 0.7 would in a segment. Maybe I'll try that. --[[User:Voidious|Voidious]] 14:34, 7 July 2011 (UTC) | ||
| + | :: /me waits for Rednaxela to come up with the ''real'' formula he should use to model the weights like the relative areas of the golden mean rectangles. =) --[[User:Voidious|Voidious]] 14:43, 7 July 2011 (UTC) | ||
| + | :: Yes, duh, I should square the golden mean since it's the ratio of the length of the sides, while the area is that length squared. And not special case sort position 1. I'm kind of excited to have something stupid like this to tinker with... =) --[[User:Voidious|Voidious]] 14:49, 7 July 2011 (UTC) | ||
| − | + | == Might have to get back into things == | |
| − | + | I don't want to have yet another person pass my highest robots ranking, and XanderCat is getting pretty close. I might have to get things in gear and start robocoding again. But considering it has been in remission for a year, not sure if I want my addiction to relapse. ;) — <span style="font-family: monospace">[[User:Chase-san|Chase]]-[[User_talk:Chase-san|san]]</span> 00:46, 12 July 2011 (UTC) | |
| − | + | :Don't worry. I just released a new version that lowered it's rank. :-P However, I am using a brand new drive and factor array system that are somewhat in their infancy (I really haven't given them enough shakedown yet, and a few bits are incomplete), so I do expect to climb back up into the top 50 eventually. I was at #49 at version 5.1.1. Still a long ways from the top, but just give me a little more time. :-) -- [[User:Skotty|Skotty]] 00:57, 12 July 2011 (UTC) | |
| − | + | :: Yeah, you we're floating right below Seraphim, and thats why I say this. I have my pride, but her weak points are all the weak bots, her strong points are all the strong(er) robots. In perspective, she can defeats 3 (over 50% score only 2 if you use survival) robots in the top 10, but defeating robots in the top 10 does not get you high into the rankings. — <span style="font-family: monospace">[[User:Chase-san|Chase]]-[[User_talk:Chase-san|san]]</span> 01:22, 12 July 2011 (UTC) | |
| − | = | + | Do you have any method of personal contact (E-mail, Messenger (AIM,Skype,Google Talk,Yahoo), IRC, Twitter), I wouldn't mind discussing things about robocode. — <span style="font-family: monospace">[[User:Chase-san|Chase]]-[[User_talk:Chase-san|san]]</span> 16:22, 12 July 2011 (UTC) |
| + | : I have an old AIM account, but I haven't been using it lately. If you are an active chat user, I could start firing it up on boot up again. Otherwise, I have an email account, but we need a secure way for me to send it to you that won't get picked up by spam bots. -- [[User:Skotty|Skotty]] 03:01, 14 July 2011 (UTC) | ||
| − | + | == Version 6.x Scores All Over The Map == | |
| − | + | Well...I'm officially confused. I've been seeing huge point swings against various opponents in the rumble even with minor changes, and it seems they are inconsistent with what I see at home. Though admittedly, I still need to put together a big stress test to get a larger performance sample. I'm still wondering if it may have something to do with missed turns, as I don't really know exactly what happens when a turn is missed (I can't find any docs that explain it thoroughly). Or maybe there are still exceptions happening. Or both, perhaps missed turns somehow causing exceptions. Hopefully I can figure it out because it is really driving me insane. Version 6.1.1 in the rumble actually lost a round to Barracuda, and that just doesn't happen. I'm going to try running v6.1.1 in the fast learning MC2K7 challenge tonight using RoboResearch, since that is already pretty much ready to go; not using any the Raiko stuff because I'm just doing it to see if any exceptions or other anomalies happen. Running 500 seasons, and will check on it in the morning. -- [[User:Skotty|Skotty]] 06:07, 12 July 2011 (UTC) | |
| + | : I think it is not help because roboresearch works with robocode version 1.6.4 and rr clients use robocode version 1.7.3 now and i notice, that there're some difference between them. If you want i can share little app, which may be called analogue of roboresearch with many restrictions, but it is designed to work with rc 1.7.3 --[[User:Jdev|Jdev]] 08:14, 12 July 2011 (UTC) | ||
| + | :: I have roboresearch working with 1.7.2.2 and have no problems with it. Don't see a reason why it shouldn't work with 1.7.3.0. --[[User:GrubbmGait|GrubbmGait]] 09:25, 12 July 2011 (UTC) | ||
| − | + | ::: As i remeber, RoboResearch requires modifications of robocode messages parser to work with last versions. But may be it was my unique troubles:) --[[User:Jdev|Jdev]] 09:37, 12 July 2011 (UTC) | |
| − | : | + | :::: You may be right, I did not get it from the source, but picked up a package of someone else (Voidious I think). --[[User:GrubbmGait|GrubbmGait]] 09:46, 12 July 2011 (UTC) |
| − | : | + | : As a note, this type of issue makes me wish that the roborumble client uploaded replay files when it uploaded results (Haha... that would take a lot of space). Actually... it would be nice even if it just uploaded skipped turn count along with the scores. --[[User:Rednaxela|Rednaxela]] 12:22, 12 July 2011 (UTC) |
| − | :: | + | :: This morning it was up to 137 seasons of the MC2K7 fast learning challenge with no exceptions or anomalies. The skipped turns thing is still just a theory. Maybe I should intentionally make it run slower at home to try and cause some skipped turns to see what happens. On that same tangent, it is probably about time I worked on my robot's efficiency so that it isn't a potential issue. -- [[User:Skotty|Skotty]] 12:45, 12 July 2011 (UTC) |
| − | + | :: On the plus side, this whole thing has prompted me to finally build some nice CPU time profiling tools. Currently taking a closer look at how long various parts of the code take to execute. -- [[User:Skotty|Skotty]] 13:44, 12 July 2011 (UTC) | |
| − | + | ::: I'm still trying to figure out what the heck is going on. In version 6.1.2, the only change was to remove a debug print line that was in a bad place, causing part of the drive code to waste a couple of milliseconds when deciding where to go for a new wave. But check out the first battle result against nat.BlackHole 2.0gamma -- my survival went from 42.86 to 8.57 (difference from version 6.1.1 to version 6.1.2). I don't know if I am on the right track on trying to improve efficiency, but something is definitely still very wrong somewhere. I suppose I should try upgrading to the latest Robocode version and see what if any change that results in (I'm currently still using 1.7.2.2) -- [[User:Skotty|Skotty]] 21:04, 12 July 2011 (UTC) | |
| − | + | :::: Definitely use the rumble version to do ALL of your testing! It can make a big difference... You could be running into bugs in the old version or possibly in the new one. | |
| + | :::: @Rednaxela, as usual you come up with interesting rumble ideas. I don't think storing a slug of data per bot would be unreasonable. Not every replay of course, but maybe a size-limited block of custom stats, exception reports, etc. The tricky part would be getting the rumble client to export it for the server, would probably require an API function. --[[User:Darkcanuck|Darkcanuck]] 21:40, 12 July 2011 (UTC) | ||
| − | == | + | == New Theory on Performance Issues == |
| − | + | I've been wondering if changing my robot to log exceptions to file is the reason for the performance anomalies. But I couldn't figure out how that would make sense until just now. Could it be that Robocode handles the following two situations differently (or perhaps, differently depending on Robocode version)? | |
| + | * Robot run() method ends due to Exception | ||
| + | * Robot run() method ends normally | ||
| + | My new theory questions whether in some instances, a robot crashes but is reactivated to finish the remaining rounds, but in other instances it is out of commission for all remaining rounds. Before I added the code to log exceptions to disk, exceptions were not caught. Now they are caught, but they are caught outside of the main while() loop, causing the run method to exit without an exception. Without knowing how Robocode internally handles the robot threads, it is hard to say what effect this might have. -- [[User:Skotty|Skotty]] 21:51, 12 July 2011 (UTC) | ||
| − | : | + | : It's been awhile, but I think that if the run() method exits, then your robot is done for the round! Doesn't robocode only call that once at the beginning of each round? You definitely want to catch and handle exceptions inside the loop so that your robot can keep playing, if possible. My bots use a while(true) loop inside run() and will never exit, except for an unhandled exception. --[[User:Darkcanuck|Darkcanuck]] 22:20, 12 July 2011 (UTC) |
| − | : | + | :: The alternative is to do a try/catch inside the while() loop. And while this would help, it would also help mask Exceptions that happen. So on one hand, I want to handle them, but on the other, it's almost better for it to crash, burn, and throw a tantrum so I will actually see the problem and correct it, rather than having it erode my robots scores quietly. -- [[User:Skotty|Skotty]] 22:33, 12 July 2011 (UTC) |
| − | |||
| − | == | + | == Debugging XanderCat -- What Next? == |
| − | + | I had at least one instance where XanderCat bugged out that ran on my own machine, but no exception report was produced (see [http://darkcanuck.net/rumble/BattleDetails?game=roborumble&name=xandercat.XanderCat%206.1.4&vs=oog.micro.MagicD3%200.41 XanderCat 6.1.4 vs MagicD3 0.41]). This means it wasn't a runaway while loop. My next step is to start writing out short data files for every robot, every round. Then at the end of the battle, if everything went normally, the files will be deleted. In those files, I will write out the number of bullets I fired, and the number of bullets the opponent fired, my round hit ratio, and the absolute distance I traveled during the round. When I see a battle that went bonkers, here are the scenarios I will be looking for: | |
| − | + | # Files present for some but not all rounds. This will indicate that the robot stopped operating completely. | |
| + | # Files for all rounds present, but bullets I fired dropped dramatically or went to 0 at same point during the battle. This will indicate that my gun stopped firing. | ||
| + | # Files for all rounds present, but my hit ratio dropped dramatically or went to 0 at some point during the battle. This will indicate that my gun was firing but the aim went bonkers. | ||
| + | # Files for all rounds present, but the number of bullets opponent fired dropped dramatically or went to 0 at some point during the battle. This will indicate I stopped detecting the opponent's fired bullets. | ||
| + | # Files for all rounds present, but absolute distance travelled dropped dramatically or went to 0 at some point during the battle. This will indicate that my drive stopped working, and my robot just starting sitting still. | ||
| − | + | Anyone have any other suggestions as to what I might look for, or other ideas on how I might try to track this down? -- [[User:Skotty|Skotty]] 13:32, 13 July 2011 (UTC) | |
| − | + | What I've done is look at every single loop in my 4000+ lines of code, checking that each one has an exit clause, and if there isn't one hardcoding one in (using a countdown). I also put a try/catch around all my code so all my other code logs exceptions to disk. Otherwise, unless you have a security manager problem everything *should* be caught. In theory =) --[[User:Skilgannon|Skilgannon]] 14:19, 13 July 2011 (UTC) | |
| − | : | + | How about try the following: Set up a script that runs robocode repeatedly, with parameters that cause it to run XanderCat 6.1.4 vs MagicD3 0.41 AND <u>save replay files</u>, and have your script delete the replay file whenever the resulting score is above 50%? I've done command line scripting of battles before it's it's fairly trivial. I suggest this method because it should catch the problem in action regardless of the cause. --[[User:Rednaxela|Rednaxela]] 14:34, 13 July 2011 (UTC) |
| − | == | + | :Switching to the most recent client for my testing was a good idea. Things are definitely different in version 1.7.3.0 than they were in 1.7.2.2. I think, for one, I have potentially fallen victim to a change in how Bullets are handled. My overall hit ratio in 1.7.3.0 keeps coming back 0, whereas it worked fine in 1.7.2.2. I have to look into it more, but I think it has to do with how I am handling the Bullets. I vaguely recall once seeing some Robocode issue related to Bullets, but I don't recall where at the moment. I'll have to dig into it more... -- [[User:Skotty|Skotty]] 21:29, 13 July 2011 (UTC) |
| + | |||
| + | :: Here it is: [http://sourceforge.net/tracker/?func=detail&aid=3312402&group_id=37202&atid=419486 bullet.equals semantic has been change in 1.7.3.0 version - ID: 3312402]. This is likely the root of all evil in my 6.x series of robots. I guess I can't trust on matching bullets by the actual Bullet objects. I will have to come up with some other way to keep track of them. After doing this, I bet all my other troubles will fade away. Note that the issue says it is ''fixed'', but it doesn't really say in what version it is fixed (was it broken in 1.7.3.0, fixed in 1.7.3.0, then re-released as 1.7.3.0, or is it fixed in the source tree but we won't see it until 1.7.3.1 or whatever the next version is?). If it is supposed to be fixed in 1.7.3.0, then I would bet the equals() method was changed without also adding or updating the hashcode() method, ultimately breaking the hashcode() contract that states: "If two objects are equal according to the equals(Object) method, then calling the hashCode method on each of the two objects must produce the same integer result." I say this because I was using Bullet objects as keys in HashMaps. If hashcode() isn't right, this would cause a HashMap lookup to fail when equals() does not. -- [[User:Skotty|Skotty]] 21:34, 13 July 2011 (UTC) | ||
| + | :::What this bug means for XanderCat, is that all the gun hit ratios are broken. The gun used is selected by the hit ratio. I give bias so that XanderCat prefers the guess factor gun, so the guess factor gun is probably still getting selected most of the time, but at other times, it probably does crazy things like selecting the linear gun and only the linear gun for the entire duration of a battle. I don't know that for sure, but it's fairly likely given the problem. -- [[User:Skotty|Skotty]] 22:10, 13 July 2011 (UTC) | ||
| + | ::: Ahhh that. That bug was reported against 1.7.3.0, and the fix is in the source tree and it will be in 1.7.3.1. As far as I understand, robocode used to give identical bullet objects, but at some point it had to give different objects due to architectural changes. The fix to 3312402 was implementing equals(). Oh, and hashcode() is also properly implemented, I checked (that was added 2 days after equals() was, both shortly after 1.7.3.0). --[[User:Rednaxela|Rednaxela]] 22:09, 13 July 2011 (UTC)--[[User:Rednaxela|Rednaxela]] 22:09, 13 July 2011 (UTC) | ||
| + | |||
| + | == Empty Output Files == | ||
| + | |||
| + | Anyone else ever have trouble with an output file being empty? I've had a lot of cases where I try to write something to a file in Robocode, where the file gets created, but it is empty and nothing gets written to it. Here is the end of my run() method (see below), that should write Exceptions to file. It usually works, but tonight I noticed I had an empty one. This was also happening with my diagnostic output files. | ||
| + | <pre> | ||
| + | } catch (Exception e) { | ||
| + | File exceptionFile = getDataFile(getName().split(" ")[0] + "_Exception.txt"); | ||
| + | log.error("Fatal exception occurred."); | ||
| + | log.error("Writing stack trace to " + exceptionFile.getAbsolutePath()); | ||
| + | RobocodeFileWriter writer = null; | ||
| + | try { | ||
| + | writer = new RobocodeFileWriter(exceptionFile); | ||
| + | String s = e.getClass().getName() + ": " + e.getMessage() + "\n"; | ||
| + | writer.write(s); | ||
| + | log.error(s); | ||
| + | for (StackTraceElement ste : e.getStackTrace()) { | ||
| + | s = ste.toString() + "\n"; | ||
| + | writer.write(s); | ||
| + | log.error(s); | ||
| + | } | ||
| + | writer.close(); | ||
| + | } catch (IOException ioe) { | ||
| + | if (writer != null) { | ||
| + | try { | ||
| + | writer.close(); | ||
| + | } catch (Exception ce) { } | ||
| + | } | ||
| + | } | ||
| + | } | ||
| + | </pre> | ||
| + | I'm not sure at the moment if the file gets created when the RobocodeFileWriter gets created, or after the first call to write. But either way, how would the file end up being empty? I did not call flush(), and maybe I should, but it really shouldn't make any difference as long as close() gets called. I am also calling log.error(String) in there, which writes to System.out, but I wouldn't think that would cause any problems. I had this same problem with my diagnostic output files...sometimes they would have data in them, other times the files would be there but empty. Thoughts? -- [[User:Skotty|Skotty]] 04:51, 14 July 2011 (UTC) | ||
| + | |||
| + | : One would think it would, but it is better to remove it as a possible factor by flushing it manually. If that doesn't work... well. To be honest I don't work with robocode File IO much. — <span style="font-family: monospace">[[User:Chase-san|Chase]]-[[User_talk:Chase-san|san]]</span> 04:57, 14 July 2011 (UTC) | ||
| + | |||
| + | :: In addition to that, there is at least one more bug I have to find, as shown by this battle: [http://darkcanuck.net/rumble/BattleDetails?game=roborumble&name=xandercat.XanderCat%206.1.7&vs=ncj.MoxieBot%201.0 XanderCat 6.1.7 vs MoxieBot 1.0]. MoxieBot got almost no bullet damage, but won half the rounds. Had to be an exception or something there. :-( -- [[User:Skotty|Skotty]] 05:01, 14 July 2011 (UTC) | ||
| + | ::: UPDATE: No exception on MoxieBot; was just due to MoxieBot using very good bullet shielding. -- [[User:Skotty|Skotty]] 15:39, 14 September 2011 (UTC) | ||
| + | |||
| + | ::: It may just be that the file operations are happening too slowly due to the large number of files in the folder. My diagnostics I had in originally created a file for every round of a battle that had anomalous results. I didn't expect battles against every single robot to have anomalous results, but they did, so there are thousands of tiny files in the folder. XanderCat 6.1.7 slowly cleans up the old files, but it will take a while before they are all gone. Maybe after the number of files is back down to a reasonable number, it will start working normally again. -- [[User:Skotty|Skotty]] 05:28, 14 July 2011 (UTC) | ||
| + | |||
| + | == New Factor Array Idea == | ||
| + | |||
| + | I have a new idea for handling factor arrays that I will be trying out soon. I've already implemented it, but haven't put it to the test yet. The idea is to start off all factor arrays with a set amount of "weight" already evenly (or close to evenly) spread within the factors. This total amount of weight in the factor array never changes. Instead, when a hit is logged, the total "weight" added by the hit is removed evenly across all factors such that the total weight in the array does not change. The weight is simply redistributed. | ||
| + | |||
| + | I'm interested to see how well it works, but at the same time, I am not very hopeful. The redistribution will act much like "rolling" (or "array decay", as I like to call it), but will only occur on an array when hits are logged to it. -- [[User:Skotty|Skotty]] 03:46, 12 August 2011 (UTC) | ||
| + | |||
| + | :This provided no improvement in practice, and it just added more complexity, so I ditched it. -- [[User:Skotty|Skotty]] 15:38, 2 September 2011 (UTC) | ||
| + | |||
| + | == Next Plans -- XanderCat 9.x -- September, 2011 == | ||
| + | |||
| + | I haven't uncovered any serious bugs in my robot, but I do have a plan for where to go next. | ||
| + | * First, and perhaps foremost, is re-assessing what segmentation is used. Over the next few weeks I will be doing a lot of RoboResearch on various segmentation combinations. Perhaps I will find that one or more of my existing segmenters is problematic, or buggy. Perhaps I will find that I just need to switch a few segmenters. Whatever the case, I think this holds a lot of potential for improvement. | ||
| + | * Second, and I have to verify this, but I do not think I am currently using information on bullet-hit-bullet events to add data points to my drive data. I drop the waves, but I think I overlooked using the information in my drive (if I know the opponents aim, I can add a data point even though I didn't actually get hit). How helpful will this be? Well, it should help the robot learn a little faster, and that could be good for a small boost. | ||
| + | * Third, I may look into utilizing bullet shadow. This may require a modification in how I process waves though. It could lead to another small overhaul of part of my framework. | ||
| + | |||
| + | It looks like you attained your top 40 goal. Congrats!--[[User:AW|AW]] 15:01, 12 September 2011 (UTC) | ||
| + | : Woot! Thank you! -- [[User:Skotty|Skotty]] 18:12, 12 September 2011 (UTC) | ||
| + | |||
| + | Using bullet-hit-bullets to add surfing data gave me quite a boost. I refactored some of my code so that instead of logging hits I log bullets (robocode Bullet objects) and it made the whole thing take an extra 6 lines of code or so =) I even do this in my surfing minibot. --[[User:Skilgannon|Skilgannon]] 06:01, 13 September 2011 (UTC) | ||
| + | |||
| + | : Take a peek at my code? Some of my drive code is still a little messy (due to playing with different ideas), but you may have noticed in my class AbstractFactorArrayProcessor, I don't do anything in the oppWaveHitBullet and myWaveHitBullet methods. I also need to start passing the actual Bullet to those methods. Regardless, it's good advice. I will put that at the top of my TODO list. -- [[User:Skotty|Skotty]] 12:44, 13 September 2011 (UTC) | ||
| + | : I didn't actually, but you know what they say about great minds ;-) Seriously, this had a noticeable impact on my surfing abilities even a minibot level, so if you want some guaranteed score get onto it ASAP. --[[User:Skilgannon|Skilgannon]] 13:25, 13 September 2011 (UTC) | ||
| − | I | + | :Just wanted to mention that a bulletHitBullet event has getX() and getY() metohds. Before I knew that, I thought adding this would be really hard, but you can basically use the same code that you use when the enemy hits you. (Remember not to log it in both the oppWaveHitBullet and the myWaveHitBullet methods)--[[User:AW|AW]] 13:56, 13 September 2011 (UTC) |
| − | I | + | ::I made this change. However, against my test bed of robots, the score increase was only 0.2 APS. This will probably translate to about 0.1 APS in the Rumble, based on how my test bed has related to it in the past. Could even be less, as I currently only run 10 seasons for my test bed. I'm pretty sure I implemented it correctly as it wasn't that complicated of a change. Would you have expected a more signficant change than that? -- [[User:Skotty|Skotty]] 15:35, 14 September 2011 (UTC) |
| − | + | :: Sorry I'm late, but congrats from me too. =) I think that would be about top 10 at the time when I joined. :-P As to your question, I would expect more of a gain than that, but maybe you'll see that in the rumble. Everything you learn from a BulletHitBullet is something you wouldn't have learned until you actually got hit by a bullet. I remember being surprised by how much it gained when I added this to [[Komarious]], but unfortunately it was right before the switchover to Darkcanuck's server and the score diff is lost forever... --[[User:Voidious|Voidious]] 16:01, 14 September 2011 (UTC) | |
| + | ::: Guess I should go back over it with a fine toothed comb and make sure I didn't make any mistakes. I'd hate to miss out on a big jump in score. :-) -- [[User:Skotty|Skotty]] 16:28, 14 September 2011 (UTC) | ||
| − | + | == New Segmenter == | |
| − | + | I may have struck a little gold in some testing tonight. I decided to try out a new segmenter, and initial results against my current test bed are surprisingly good. Maybe a big part of my problem is not bugs I can't find, but things like not having the right segmenters yet. The new segmenter will see action in version 9.0 of XanderCat, which I expect to have done on or before this weekend. -- [[User:Skotty|Skotty]] 01:37, 9 September 2011 (UTC) | |
| − | + | == Version 9.5 - Interesting Results == | |
| − | |||
| − | + | Version 9.5 included switching to using my data from time-2 for opponent waves, and a first run of surfing multiple waves. The results were interesting. | |
| − | + | First off, something weird happened against YersiniaPestis 3.0 on darkcanuck's server. I highly doubt the 2 scores of 90 against it are legit. That would be vudu magic. | |
| − | + | Scores in general are more varied than in previous versions, but that could just be because there are not enough battles yet. So far scores against Barracuda and HawkOnFire are up, which can be credited to the second wave surfing. | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | I'm seeing a few skipped turns for the first time ever. That is due to the extra processing required to do the second wave processing. I need to go back and see if I can make it more efficient now. I also haven't fine tuned the second wave processing, so there could be some more points to pick up there. | |
| − | + | I had played with rolling drive data with some mixed results before releasing this version. However, for this version, I decided to continue not rolling any data. I need to do more analysis on this before I try to change it (or even if). {{unsigned|Skotty}} | |
| − | I' | + | : One cool speed optimization for multi-wave surfing, which I think [[User:Krabb|Krabb]] taught me: After calculating the danger on the first wave, don't bother calculating second wave dangers for that movement option if the first wave danger is already higher than the best danger you've calculated so far. (Sounds obvious now... =)) If you also calculate the safest movement option from last tick first, that helps even more. Overall it's a really nice speed increase with no change to behavior. --[[User:Voidious|Voidious]] 15:11, 20 September 2011 (UTC) |
| − | + | : Yep, this optimization is the only thing that stops DrussGT from falling over flat. I first do all my first-wave predictions, then sort them in ascending danger. As I go through, once I get a first wave danger that is higher than my lowest first+second wave danger I know I can immediately quit because the dangers will only be higher after that. Brilliant solution. Another thought is that you might want to play with the weighting of the different waves - I found that inverse time-till-hit worked quite well. Waves that are closer are higher priority, and waves that are further away can be dealt with, for the most part, later. --[[User:Skilgannon|Skilgannon]] 06:02, 22 September 2011 (UTC) | |
| + | : Just on a sidenote: dangers don't change if there is no new info, so you only have to recalculate them if new info is present (bullet hit, bullet hit bullet). You still have to determine the complete danger for f.e. multiwave, but that is just peanuts. But maybe I am just talking VCS and is DC a complete other situation. --[[User:GrubbmGait|GrubbmGait]] 08:56, 22 September 2011 (UTC) | ||
| + | :: Nah, it's the same for other systems such as "DC" too. --[[User:Rednaxela|Rednaxela]] 13:04, 22 September 2011 (UTC) | ||
| + | :: Except that in my true surfing (and I suspect many others), waves are weighted by time to impact, which changes tick by tick. This is the big thing I'd grapple with if/when I try some go-to surfing. {{unsigned|Voidious}} | ||
| + | :: Sorry, just to elaborate: You could, of course, cache the danger before applying time to impact. And, more conservatively, you could cache the precisely predicted locations that should be identical for whichever predicted path you moved along last tick. Historically, I've not done this because it seems ugly and error-prone, but I'm almost inclined now to give it a shot. --[[User:Voidious|Voidious]] 14:41, 22 September 2011 (UTC) | ||
| + | ::: Well, to start with, I haven't done correct multi-wave surfing yet (still re-writing my movement) but I don't see why weighting waves by inverse time to hit could help except that it is more probable that your data on the waves that will hit later will be updated. Is there any other reason to weight the waves by time to hit if you are calculating all movement options for the second (or third etc.) wave?--[[User:AW|AW]] 15:07, 22 September 2011 (UTC) | ||
| + | ::: The short answer is: I didn't think I needed to either when I first did my branching multi-wave surfing algorithm, but it performed better if I did. =) (I knew other bots weighted by time to impact.) But I can rationalize it. With True Surfing, each tick you're considering 2-3 movement options. When the two waves are 15 and 30 ticks away, it's unlikely that any of the 2-3 spots you're considering are where you'll finally end up - it's more of a "broad strokes" calculation to determine a direction, so considering both waves is important. As the first wave gets closer, it's more important to really decide which spot exactly on that wave you think is safest, and the second wave options for each of those spots are getting more and more similar anyway. When the nearest wave is only 3 ticks away, there is a ton of overlap on the second wave options. It's kind of silly to put a lot of weight on which 2-3 points come up for each of the second wave options - those same points might be reachable from any of your first wave options, meaning it's just random noise which ones happened to come up for each first wave option. --[[User:Voidious|Voidious]] 15:18, 22 September 2011 (UTC) | ||
| + | ::: I can definitely see how it should help with that, but if your robot predicts every possible movement option, I would think that there is a better way to do this. To rephrase my idea, suppose you could see the enemy's bullets, then the safest movement option (or rather a safe movement option) would be where neither bullet would hit you. Now suppose the enemy fires waves with bullets of different powers at different angles and you could see these, the safest movement option would be the one that minimizes your damage. The assumption I am making is that if instead of multiple bullets at each angle you had an estimate of the probability he would shoot using any given angle this would still be the best possible movement option. I am pretty sure this is correct, but I need rednaxela to verify it. If this is the case, then the weighting of each wave should be based on the probability that your best estimate will change before the wave breaks.--[[User:AW|AW]] 16:28, 22 September 2011 (UTC) | ||
| + | ::: I'm somewhat intrigued by what Skilgannon said. Bare in mind that XanderCat uses GoTo surfing. Right now, I start by picking a first and second choice on the first wave, then use those two points as starting points for the second wave. But I may have been more in a true surfing mindset when I set it up that way. Using Skilgannon's approach, I could consider a range of possibilities for the first wave, not just a first and second choice, ordered by danger and short-circuting second wave checks in the manner Skilgannon described. So long as I can keep it reasonably efficient, I'm willing to bet that will give me another performance boost. I'll have to experiment more with wave weighting as well. Right now, I weight the first and second waves equally regardless of their proximity, for much the same reasons as AW is speaking of, but I haven't really put a lot of thought into it yet. -- [[User:Skotty|Skotty]] 20:23, 22 September 2011 (UTC) | ||
| + | ::: You really should consider the closest wave more dangerous, just like dodgeball. The first wave limits your range to move the most, while the second wave decides which direction to move if for the first wave the danger is almost the same on the whole range. Normally there is time to reach a reasonably safe spot when the second wave becomes the first wave, although it is true that the safest spot for the second wave can be out of reach because you had to dodge the first wave. Hmm, maybe I have to rethink my second-wave implementation, because currently it is just a first-wave calculation with a lower weighting. --[[User:GrubbmGait|GrubbmGait]] 21:18, 22 September 2011 (UTC) | ||
| + | ::: Another reason to weight the first wave higher is that it is certain that this is the information you will be surfing. When surfing the second wave as the new first wave (once the current first wave has passed) there will be a new second wave, so the stats will have changed. Because of this, although the second wave can certainly help with choosing where safe locations will be, there is a high probability that once you factor in the wave after it as well it will change quite a bit. Because of this, weighting the closer waves higher seems to help, or at least this is my thinking. Another thing that changes is distances - if the enemy robot moves right next to where your third wave safe points will be, that area is no longer as safe so the data you were surfing earlier is now useless.--[[User:Skilgannon|Skilgannon]] 06:43, 23 September 2011 (UTC) | ||
| − | + | == Melee Rumble == | |
| − | + | I finally started working on some components for the melee rumble. I was thinking I would add them as another ''scenario'' to XanderCat, but I'm not sure if I really want to add that extra bloat to it or not. I could release an entirely different robot for melee-only (same framework though). But I like the idea of adding it to XanderCat to expand on it's presence and multi-mode nature. | |
| − | + | I finished a melee radar, and about half finished a melee gun. Still need to write a drive. My framework needed some minor adjustments to fully support melee combat, but nothing significant. It shouldn't be too long before I can put them to use. | |
| − | + | == Best Bot Page Candidate == | |
| − | + | I just wanted to say that I find your extensive information on how your built your bot and why to be an invaluable well of inspiration. If we had a reward for best bot page I would but XanderCat's up among the top. It might be the #1 even, I haven't looked around too much lately. Thanks! -- [[User:PEZ|PEZ]] 09:40, 4 November 2011 (UTC) | |
| − | :I | + | :Thank you! I still feel it needs further improvement, but I have indeed put a lot of work into it. Parts of it are still in a state of semi-experimentation, and I do change things periodically. I try to keep the pages on the wiki up-to-date, but feel free to contact me if you have questions about some of the things that I have done, or if you are wondering if something I have written is still accurate, or if you just want to chat about design options or ideas. And welcome back! I'm happy to see you back in action! -- [[User:Skotty|Skotty]] 01:23, 5 November 2011 (UTC) |
| − | : | + | == KD-Tree == |
| − | + | Are you using Red's 3rd generation tree [https://bitbucket.org/rednaxela/knn-benchmark/src/tip/ags/utils/dataStructures/trees/thirdGenKD found here]. It uses parts from the dataStructures directory, so keep that in mind. — <span style="font-family: monospace">[[User:Chase-san|Chase]]-[[User_talk:Chase-san|san]]</span> 21:41, 1 December 2011 (UTC) | |
| − | |||
Latest revision as of 00:48, 16 February 2013
Congrats on breaking the 50% barrier. Seems that you have the planning of your bot on scheme, now it's just the translation into the right code. One small remark: You don't have to have 'zillions of versions' present in the rumble, the details of older versions still are available when not in the participants list anymore. Comparisons between two versions are quite easy to do like [1] . Just click on your bot in the rankings, then the details and a few older versions are shown. Good luck with your further development! --GrubbmGait 08:37, 25 May 2011 (UTC)
- Thanks GrubbmGait, though I'm not sure how much praise I deserve for being officially average. :-P I'm trying out a slightly revised version today, version 2.1. No major component changes, but it modifies the bullet firing parameters, driving parameters, some segmentation parameters, and has improved gun selection. Skotty 20:43, 25 May 2011 (UTC)
Contents
- 1 Rethink / XanderCat 4.8+
- 2 Case Analysis
- 3 Which Waves to Surf
- 4 Rolling Average
- 5 #1 Against PolishedRuby
- 6 Fixing My Wave Surfing Rolling Depth
- 7 Might have to get back into things
- 8 Version 6.x Scores All Over The Map
- 9 New Theory on Performance Issues
- 10 Debugging XanderCat -- What Next?
- 11 Empty Output Files
- 12 New Factor Array Idea
- 13 Next Plans -- XanderCat 9.x -- September, 2011
- 14 New Segmenter
- 15 Version 9.5 - Interesting Results
- 16 Melee Rumble
- 17 Best Bot Page Candidate
- 18 KD-Tree
Rethink / XanderCat 4.8+
I lost some ranks when I refactored the guess factor and wave surfing code in version 4.7, and have yet to get them back. But I'm still convinced the refactor was a good thing.
I've ironed out all the major bugs, and if I watch XanderCat in some battles, I don't see it doing anything obviously wrong. This got me thinking about how I handle segmentation again. I think my philosophy on balancing segments for comparison was wrong in the drive, and am changing it in version 4.8. I also plan on excluding certain segment combinations that when I think about them, just don't make much sense (like using just opponent velocity). I think this should improve performance.
Beyond this, I'm not sure what I would do next to try to improve. I could run zillions of combinations of segments and parameters just to see what seems to work better against a large groups of robots that I think is representative of the whole. Not sure I will go to that extent though. Skotty 01:09, 22 June 2011 (UTC)
I'd definitely say that you still have non-negligible bugs / issues with your surfing. Looking at Barracuda and HawkOnFire again, compared to DrussGT we have 95.82 vs 99.83 and 97.91 vs 99.91. In other words, both are hitting you ~20x as much, totally unrelated to how you log/interpret stats (because they're HOT). Not to be a downer - XanderCat is coming along great and you appear to have a really robust code base. Or if you're burning out on 1v1, how about Melee? It's a much different animal. =) --Voidious 01:28, 22 June 2011 (UTC)
- It appears as though I'm on the right track with version 4.8. Just for you Voidious (grin), in addition to other changes, I configured it to maximize scores against head-on targeters, which raised the Barracuda and HawkOnFire scores to 98.98 and 98.76 respectively (2 battles each so far). To get the rest of the way to DrussGT levels, I will need to tweak my dive protection a little more; it still causes XanderCat to stall near a wall long enough to be hit every once and awhile. I may need to also tweak my "Ideal Position Drive" a bit more too, as it still drives too close to opponents occasionally when trying to reach an ideal position (the Ideal Position Drive drive runs at the start of each round before bullets start flying).
- Nice. =) For better or worse, the RoboRumble greatly rewards bots that can annihilate HOT and other simple targeters, so you might be surprised by how much of a ranking increase you can find by polishing that aspect of your surfing. It's not always the sexiest thing to work on, nor the most fun... But more importantly (to me), it's just a good way to verify that your surfing is working how it should. I can't find a good quote, but both Skilgannon and Axe have commented on the fact that if even a single HOT shot hits you, there's something wrong. --Voidious 17:51, 22 June 2011 (UTC)
- Very true. A wavesurfing bot should be able to dodge all *known* bullets perfectly, and HOT is only known bullets. Unless there is something funky like bullets fired from 20 pixels away, or a gun cooling time of 1 tick, all bullets *should* be avoidable.--Skilgannon 11:54, 23 June 2011 (UTC)
- Nice work, but just as a note, some might think me crazy, but I don't think *any* explicit dive protection is necessary for this sort of thing really. My surfing bots RougeDC and Midboss (same movement code), get 99.5% against HawkOnFire with no explicit dive protection whatsoever (and in certain past versions they did even better IIRC). The thing is, as I see it, dive protection is completely unnecessary if the surfing properly considers how movement changes botwidth. I much prefer it that way as it doesn't require tweaking/tuning to get right. Just my 2 cents on dive protection. --Rednaxela 20:50, 22 June 2011 (UTC)
- Well, I'd still call it "dive protection". =) But yes, I agree that multiplying danger by bot width (or dividing by distance, which I think is still what I do) is about the most elegant solution. And I doubt anyone's calling you crazy. Do any top bots since Phoenix use special cases? I guess I'm not sure about GresSuffurd or WaveSerpent. --Voidious 21:14, 22 June 2011 (UTC)
- Oops, I guess I'm out of touch. Diamond still has special cases, despite taking this approach - it scales the danger more than linearly beyond a certain threshold, as Dookious did. Maybe I'll test removing that, just for the sake of argument. =) I think it will lose points, though. Sure, for one bullet, the danger scales linearly with bot width. But that bot width affects future waves too. I suppose whether this is "explicit dive protection" would be up for debate. --Voidious 21:24, 22 June 2011 (UTC)
- Hmm...considering my own robot width when surfing...why didn't I think of that before? Guess what new feature will be in version 5.0? :-D Skotty 22:44, 22 June 2011 (UTC)
- Rather than multiplying danger by bot width, I prefer integrating over the affected bins, since many bins can be covered at close range... ;) --Rednaxela 22:49, 22 June 2011 (UTC)
- GresSuffurd has 2 lines of code handling both distancing and dive protection. This code hasn't been changed for years. The dive protection just handles the angle, not the danger. My latest effort was to use the summed danger of all covered bins instead of the danger of one bin to decide which direction to go(forward, stop, backward), but this approach let me fall out of the top-10 ;-) Sometimes a simple, proven, not optimal solution works better than a theoretical optimal solution. I do like the idea of letting danger instead of angle decide when to change direction though, and I will continue in this path with the next versions. Welcome to the dark caves of Robocode. --GrubbmGait 23:25, 22 June 2011 (UTC)
- If it's ever pitch black, watch out for GrubbmGait's pet Grue ;) --Rednaxela 00:21, 23 June 2011 (UTC)
- I think the reason these approximations often work better is that we're using a discrete system, and often the optimal assumes continuous. I think the other reason is that the optimal system often gets horrendously complex and bugs creep in, making the simple system actually more accurate. But these are just thoughts =) --Skilgannon 11:54, 23 June 2011 (UTC)
- Well, in this specific case, I would say the "optimal system" doesn't get more complex. I would argue integrating over botwidth is less complex, because:
- It also implicitly does the most important part of what many people use bin smoothing for
- There aren't really any parameters to need to tune
- To be clear, a very very very tiny amount of bin smoothing is still useful, to cause it to get as far as possible from danger, but the integrating over botwidth really does the important part of the smoothing. Actually, I suspect that if people get lower scores with integrating over bins, it's because it overlaps with their existing smoothing which has become far too strong.
- Basically, sometimes the "optimal system" may actually be less complex. It can reduce how many tunable parameters are needed, and also replace multiple system components necessary to fill a purpose. --Rednaxela 13:37, 23 June 2011 (UTC)
- Well, in this specific case, I would say the "optimal system" doesn't get more complex. I would argue integrating over botwidth is less complex, because:
- I also think we tune around a lot of arbitrary stuff in our bots. I remember PEZ and I often lamented how something we'd set intuitively, and "couldn't possibly be optimally tuned!", resisted all attempts to tune it. I imagine that's sometimes the case when an existing simple/approximate approach performs better than the "new hotness totally scientifically accurate" approach. Dark caves indeed. =) --Voidious 14:48, 23 June 2011 (UTC)
- For the record, I don't use binsmoothing, as I don't see the purpose of it. If a safe spot is near danger or far away from danger does not matter, it is still a safe spot. --GrubbmGait 19:16, 23 June 2011 (UTC)
- Oops, I guess I'm out of touch. Diamond still has special cases, despite taking this approach - it scales the danger more than linearly beyond a certain threshold, as Dookious did. Maybe I'll test removing that, just for the sake of argument. =) I think it will lose points, though. Sure, for one bullet, the danger scales linearly with bot width. But that bot width affects future waves too. I suppose whether this is "explicit dive protection" would be up for debate. --Voidious 21:24, 22 June 2011 (UTC)
Case Analysis
Just out of curiousity, does anyone have any insight as to why deo.FlowerBot 1.0 drives so predictably against gh.GresSuffurd? I can't figure it out. FlowerBot just drives around in a big circle when fighting GresSuffurd, while seeming far less predictable against XanderCat 4.8. Maybe it's a distance thing? Looking a little closer, I see that a lot of top robots are only getting about 70% against FlowerBot, so perhaps it's just a lucky tuning on the GresSuffurd matchup (or unlucky, in the case of FlowerBot).
I'm hunting around to find cases where XanderCat performs poorly in cases where top robots perform very well. So far I haven't found a case I can learn anything from. I'll keep looking...
Flowerbot has a bug. This bot is derived from the (original) BasicGFSurfer which had a flaw when bullets had a power of x.x5 It could not match the bullet to a wave due to a bug in the rounding, therefor it did not 'count' the hit as a hit in its surfing. Just try out and always fire 1.95 power bullets at it, you will obliterate it. There are still some more bots using this codebase, so this 'bug-exloiting' could gain some points for you. --GrubbmGait 19:25, 23 June 2011 (UTC)
- Yep. That's it. Skotty 19:35, 23 June 2011 (UTC)
Which Waves to Surf
Anyone tried surfing all enemy waves at the same time? XanderCat currently surfs the next wave to hit, but I've been thinking about trying to surf all enemy waves simultaneously. Not sure if it would be worth trying or not.
Yep, many modern bots do. I surf two waves and weight the dangers accordingly. Doing more or all waves (would be just a variable change) would have almost no effect on behavior, because 3rd wave would be weighted so low, but cost a lot of CPU. --Voidious 19:45, 23 June 2011 (UTC)
In addition to what Voidious says, I'd like to note that going beyond two waves without eating boatloads of CPU could perhaps be done if one tries to be creative. One option is doing something like two and a half waves. What I mean by "half" is for the third wave, taking an approximate measure such as "If waves 1 and 2 are reacted to in this way, what is the lowest danger left for wave 3 that is approximately possibly reachable?". That approach leaves the branching factor of the surfing equal to 2-wave, but allows the 3rd wave to break ties in a meaningful way. Now... I haven't actually tried this, but just a thought about how to go beyond 2 without eating too much cpu. It might help in cases where the reaction to the first two waves would normally leave it particularly trapped... --Rednaxela 21:16, 23 June 2011 (UTC)
- I'm trying out surfing 2 waves at once for version 5.0, but I'm not sure how well it will work. I'm currently weighting the danger of the closer wave at 80%, and the 2nd wave (if there is one) at 20%. This is more a gut feeling for now. I may have to change it later. On a related note, version 5.0 pays more attention to robot width, such as determining when enemy bullet waves hit and when they are fully passed, but I was torn as to when to stop surfing the closest wave. Do I continue to surf it until it is fully passed, or do I stop surfing it right when it hits to try to get an earlier start on the next wave? For now, I'm doing the latter. Skotty 13:15, 24 June 2011 (UTC)
- About weighting between the waves, I believe one popular approach is weighting by (WaveDamage+EnergyGainOpponantWouldGet)/(distanceWaveHasLeftToTravel/WaveSpeed). This approach is nice because it gives a reasonable weighting of waves in "ChaseBullet" scenarios.
- As far when to stop surfing a wave... what I personally do, is surf the wave until it has fully passed, BUT I reduce the danger to 0 for the exact range of angles that would have already hit me (this is all using Precise Intersection to determine what range of angles would hit for each tick). This means that a wave that has almost completely passed me, will still be getting surfed, but care about those few angles that could still possibly hit (meaning, very low weight often). --Rednaxela 16:47, 24 June 2011 (UTC)
- Yeah, (damage / time to impact) is good, maybe squared. I can't remember if XanderCat is reconsidering things each tick (ie, True Surfing) or not, where that formula makes sense. While Rednaxela's setup is by far the sexiest, in a less rocket sciencey system (such as Komarious), I definitely favor surfing the next wave sooner - like once the bullet's effective position* has passed my center. (*Dark caves note: in Robocode physics, a bullet will advance and check for collisions before a bot moves. So for surfing, I add an extra bulletVelocity in cases like this.) --Voidious 17:53, 24 June 2011 (UTC)
- Originally, XanderCat was reconsidering things each tick, but I was running into what I referred to as "flip flopper" problems, where XanderCat would keep changing it's mind, and it seemed to be hurting performance. So I switched it to only decide where to go when a new bullet wave enters or leaves the picture (plus it processes less that way). However, I could see reconsidering every tick as being superior with the kinks worked out, and the "go to" style surfing has problems with dive protection. I therefore just modified my drive again to make the frequency of surfing configurable -- a hybrid approach between "go to" surfing and true surfing -- where I can set the max time to elapse before a reconsideration is performed; if the waves in play haven't changed before the time limit elapses, a reconsideration is executed. This becomes true surfing when you drop the time limit to 1. Not sure what value I will use for 5.1+ yet. Skotty 19:59, 24 June 2011 (UTC)
Rolling Average
I notice you say you are using a very high rolling average in both movement and gun. I have found in DrussGT that the gun should have a very high rolling average, but the movement a very low one to deal with bots that have adaptive targeting. By low I mean less than 5 on very coarsly segmented buffers, and less than 1 on finely segmented buffers. But I suggest you experiment with your own data and figure out what works best for you =) --Skilgannon 10:35, 27 June 2011 (UTC)
#1 Against PolishedRuby
I just checked for fun, and found that XanderCat currently holds the #1 score against PolishedRuby! Only 2 battles in the rumble, and only best by a slim margin, so XanderCat could slip down. But for the moment, I would like to claim my virtual gold medal against mirror bots. :-D —Preceding unsigned comment added by Skotty (talk • contribs)
Well, seems you certainly have a good anti-mirror system in place. I've never gotten around to building one of those... --Rednaxela 06:18, 1 July 2011 (UTC)
Fixing My Wave Surfing Rolling Depth
I think it is time for me to go back and really think about how I am processing segments to get a low rolling depth working properly on XanderCat. Let me start by giving a quick explanation of how I store my data, as it may be a bit different than what most robots do.
First off, I currently record two types of information. Hits and visits. Hits are recorded in a factor array using bin smoothing similar to what BasicGFSurfer does, and visits is just an incremented integer that says I was at a particular segment combination for a bullet wave, which I do for all bullet waves.
I store all of my wave surfing hit data in a 2-dimension array. The first dimension is the segment, the second dimension is the factors/bins. I can use any number of different segmenters. How this works is that I index all segmenters into the single segment array. So lets say I have segmenter A with 4 segments, and segmenter B with 3 segments, and 87 bins. My hit data array would then be a double[12][87] (3*4=12 segment combinations, 87 bins).
I store all of my wave surfing visit data in a 1-dimension array of int. Following in the former example, it would be an int[12] array. At present, this is used to balance the arrays when picking the best one (by dividing by total visits) and to decide whether or not I will consider using a particular segment combination. (e.g., I can say not to use a particular segment combo until it has seen at least X number of visits).
When I want to consider a particular segment combination to use for surfing any particular wave, I pull back all the indexes that match that segment combination and add the bin arrays for those indexes into a single combined array.
When I added rolling depth support, I was only thinking of rolling off hits. I created a List<List<Parms>> for this, where Parms was just a little class that holded the necessary information to roll back a previously added hit. The outer list index matched the segment index, while the inner list stored data for X number of hits. Once the list reached the preset rolling depth value, for every new hit it would remove the oldest hit from the list and roll it back. So, for example, lets say I get hit, and the combined segment index is 5, factor 23. This would get added to the hit data array (lets call this hitArray) centered at hitArray[5][23]. The hit would also get recorded in the rolling depth list (lets call this rollData) at rollData.get(5).add(new HitParms(...)). If the roll depth had been exceeded, it will then remove the oldest hit data in the list (rollData.get(5).remove(0)) and roll the old hit off the hitArray (same as adding a new hit, only it uses the saved data and applies a negative hit weight to remove the old hit).
To complicate things a tad further, I also add what I call a base load to whatever array is to be used for the current surf wave (this base load doesn't actually get added to the hitArray, it is added to a temporary array used for surfing the current wave). This base load is just the equivalent of a single head-on hit. It gets lost in the background when there is a lot of hit data, but is crucial in the beginning to avoid getting hit by head-on targeting.
And finally, I also store a combined no-segment array seperately, which I rely on early in the match when the segment combinations do not have a visit count over a certain threshold. I could obtain this by adding all segment arrays, but this seemed excessive, so I just store it in a separate array.
Given all this, I'm left wondering a few things. One, what do the rest of you really mean when you talk about having a rolling depth of 1 or 2. Are we talking rolling for every visit, every hit, or something else? Two, how should I handle avoiding head-on early in the battle when there is no data to rely upon without it messing up trying to use a low rolling depth (and will my current base load approach suffice for this)? Three, as I currently have it implemented, I can only roll hit data for all segments combined. I might could manually roll on the fly in the temporary array used for surfing, but I need to figure out what the rest of you are really talking about when you refer to rolling depth before I try such a thing.
—Preceding unsigned comment added by Skotty (talk • contribs)
Well, the usual "rolling average" method used in most targeting is far far simpler than what you describe. Usually exponential moving average is used. Instead of decrementing old hits, you just decay the weighting of old data. In a system like you describe with "hits" and "visits" kept separate, the exponential rolling average strategy would be, when you get a hit in a segment:
- First, multiply all values in "hits" and "visits" by a constant between 0.0 and 1.0.
- Then add your new hit and new visit, but multiply each by 1 minus the constant.
For an example, if you choose a constant of 0.5, then it means that with there is a hit in the segment, the old data will be worth half as much as before. Also, some bots do it slightly differently so the decay is constant, rather than only occurring when a segment is hit, though that takes a little more work to do efficiently.
The method you describe should work too, if you decrement both visits and hits when decrementing old hits I believe. I'm pretty sure decrementing both would be necessary to keep the values sane. Personally, I don't consider it worth the complexity, but diverse techniques is always interesting. :)
About the "base load", I'm pretty sure most bots do either of the following two things:
- Initialize the data to contain the "base load" (which means that in an exponential moving average system, it'll decay away to near-nothing pretty fast)
- or, make the "base load" a special case that only applies when there are no hits in the segment.
Hope that helps. --Rednaxela 23:56, 6 July 2011 (UTC)
Ok, a few things to tackle here. =)
- What most VCS / GF bots do is for each bin, the danger value is a number between 0 and 1. When data is logged for a segment, the value for each bin in that segment becomes
((rolling depth * old value) + new value) / (rolling depth + 1). The "new value" would be 1 for the hitting bin, some bin smoothed value < 1 for the rest. You might usemin(rolling depth, times his segment has been used)instead of rolling depth, a trick I learned from PEZ - ie, use the straight average if you don't have rolling depth's worth of data. A rolling average of 1 means all previous data is weighted exactly equal to the new data. There's no magical reason you need to use this style of rolling average, but it's pretty simple and elegant. Bots that don't use segments have to come up with different styles of data decay. - What you're referring to as a "visit" isn't what most of us are referring to. Generally, a visit is to a bin, not (just) a segment. A visit means "I was at a GuessFactor when the wave crossed me", as opposed to "I was at a GuessFactor when a bullet hit me". A visit is what a gun or a flattener uses to learn. What you're referring to as a "visit" is what you'd use in the min(rolling depth, x) example above, I think.
- About hard coding some HOT avoidance... Many bots use multiple buffers at once and sum the dangers from all buffers. In that case, you can just have one unsegmented array and load it with one shot at GF=0 instead of looping through every segment of all buffers. There are other benefits to summing multiple buffers of varying complexities, like having a balance between fast and deep learning (without having to figure out when to switch). In Komarious, I just add a tiny amount of danger smoothed from GF=0 after I poll my stats - mainly a Code Size-inspired trick, but not a bad approach. Diamond just uses a smoothed GF=0 danger when he has no data - this is only until the first time he's hit since he uses Dynamic Clustering.
Hope that helps! --Voidious 01:41, 7 July 2011 (UTC)
- And just a quick note to be clear, the "((rolling depth * old value) + new value) / (rolling depth + 1)" formula that Voidious cites is exactly mathematically equivalent to the method I was going on about above. It's just that the constant I used in my explanation is equal to "(rolling depth / (rolling depth + 1))". Two different ways of describing the exact same thing. Personally, I find what people sometimes term the "rolling depth" number less intuitive than the "what to multiply the old data by" constant, but it's really a matter of personal taste. I just through I'd point the equivalence out. :P --Rednaxela 02:07, 7 July 2011 (UTC)
What Voidious describes is exactly what I used to do - keep a whole bunch of buffers, where the bins represent the hit probability at that guessfactor, and when logging a new hit use a 1/((i-index)*(i-index) + 1) binsmoothing technique coupled with that rolling average formula he gave. There were 2 main problems: execution time (slow), and memory usage (high). I did what I could to get around this by hoisting the inverse of all the divisions outside of the loops and switching to floats, but that only helped so much. So, a while ago I changed my data-logging in DrussGT: instead of a whole bunch of arrays of smoothed hits - with around 100 bins - I instead now keep the guess factor of the last 2*rollingDepth + 1 hits. Each hit I weight less and less exponentially, by logging each hit into the bin it corresponds to (this is at wavesurfing time), and incrementing that bin with a value that gets progressively smaller. The factor I use for making the increment get smaller is roll = 1 - 1 / (sb.rollingDepth + 1), and each time I go through the loop I make the increment smaller by doing increment *= roll. By carefully choosing a starting value for increment I was able to make this system perform identically to the one that used the rolling average formula above while using a fraction of the CPU to log hits and a fraction of the memory to store them. Once all the hits are logged into their bin, I take this array of unsmoothed hits and smooth them. This has the huge advantage of taking any duplication of hits and essentially merging them again, speeding up the process further. Bins that don't have hits in them don't need to be smoothed, and in practice there are quite a lot of bins that are empty. Data logging has been sped up because instead of smoothing data into hundreds of buffers, each with a hundred bins, instead I just shift the hits over by one in these hundreds of buffers and add the new hit to the beginning. There are a few other tricks that I used to speed up the whole process, like only allocating the array for the hits once that segment has been hit and pre-calculating the indexes for all the buffers I need to access. But choosing this system has essentially eliminated all the skipped turns DrussGT used to experience, while still keeping all of my hundreds of buffers and all of my original tuning intact. --Skilgannon 09:23, 7 July 2011 (UTC)
- That's an interesting approach. It seems to me though, that once you're storing a list of hits, why not forgo bins entirely? It seems like it would be simpler and have essentially the same result. Maybe I'm wrong, but I'd think performance could also be improved further, with a method that instead of adding many sets of bins, concatenates a list of the
2*rollingDepth + 1hits from each segment, along with the weighting for each list entry. Then instead of calculating the value for a bunch of guessfactor bins, take advantage of knowing the integral of the smoothing function to do a fast and precise calculation of where the peak would be. Just a little thought. --Rednaxela 12:37, 7 July 2011 (UTC) - I've toyed with the idea of using some sort of DC system as a replacement, but the lack of rolling data makes me very hesitant. Also, it's not enough just having one peak (maybe you were thinking of targeting?): I need the danger at every point on the wave. I could use the raw data at each point I need to check, which would be slow, or I can take a whole bunch of evenly spaced samples, which is basically bins, which is what I am doing. My explanation was a bit complex I think. Perhaps a simpler explanation would be: when logging a hit, instead of smoothing the hit into a buffer, put it into a que (of which many exist, at their own 'location' just like a segmented VCS system) and delete the oldest entry in the que. When the time comes to stick the hits into a wave, go through the que and increment the bin in your 'wavebuffer' that corresponds with the GF of each hit in each que. Make sure that the older items in the ques are weighted exponentially lower. When you've put all the hits into that buffer, use a smoothing algorithm to, essentially, 'fill in the blank areas'. That's basically it, the rest is just implementation details.--Skilgannon 13:42, 7 July 2011 (UTC)
- By forgoing bins I never meant using DC. I mean segmented queues of hits like you have, but use non-bin methods to sum the data and find the peak. When not using bins for storage, I kind of feel it's a silly/wasteful to use bins for analysis of the stored data. As a note, I think DrussGT's movement may be the first actual implementation that fits the segmented log-based guessfactor category. See this chart I made a while back:
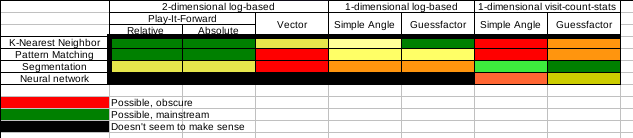
- --Rednaxela 14:01, 7 July 2011 (UTC)
- I think WaveSerpent might fit that too. (Maybe just WaveSerpent 1.x.) And, even further off-topic, I think ScruchiPu and/or TheBrainPi might belong in one of those black NN slots - for some reason I thought I recalled them being fed the tick by tick movements, not the firing angle / GF. --Voidious 15:59, 7 July 2011 (UTC)
- I think ScruchiPu and/or TheBrainPi are off this chart entirely. IIRC they are fed by tick by tick movements yeah, but that's neither log-based or visit-count-stat based, so it wouldn't fit in the black slots. It would go in it's own column. As subtype of "play-it-forward" but not a subtype of "2-dimensional log-based". --Rednaxela 16:32, 7 July 2011 (UTC)
- I think WaveSerpent might fit that too. (Maybe just WaveSerpent 1.x.) And, even further off-topic, I think ScruchiPu and/or TheBrainPi might belong in one of those black NN slots - for some reason I thought I recalled them being fed the tick by tick movements, not the firing angle / GF. --Voidious 15:59, 7 July 2011 (UTC)
- Off-topic, but... Decaying surf data in a DC system is kinda interesting. Designing a system for it in Diamond really made me appreciate VCS / rolling average. =) Instead of weighting things by age, I sort my "cluster" inverse-chronologically and weight each hit according to its sort position. I actually tried hard to figure out how to emulate a rolling average of 0.7 - the most recent data is weighted about 60/40 to the rest of the data, 2nd most recent is 60/40 to the rest of the rest, etc. That got me thinking about the golden mean, like in this image. I weight the most recent scan 1, and the rest by (1 / (base ^ sort position)), with a base of golden mean = ~1.618. So it's 1, .38, .24, .15. I figured the golden mean was cool and magical and this modeled rolling average = 0.7 pretty well, so I stuck with it. =P The first one basically gets a sort position of 0 instead of 1.
- Come to think of it, I really could model it to just weight it exactly how a rolling average 0.7 would in a segment. Maybe I'll try that. --Voidious 14:34, 7 July 2011 (UTC)
- /me waits for Rednaxela to come up with the real formula he should use to model the weights like the relative areas of the golden mean rectangles. =) --Voidious 14:43, 7 July 2011 (UTC)
- Yes, duh, I should square the golden mean since it's the ratio of the length of the sides, while the area is that length squared. And not special case sort position 1. I'm kind of excited to have something stupid like this to tinker with... =) --Voidious 14:49, 7 July 2011 (UTC)

{kind=link}
Might have to get back into things
I don't want to have yet another person pass my highest robots ranking, and XanderCat is getting pretty close. I might have to get things in gear and start robocoding again. But considering it has been in remission for a year, not sure if I want my addiction to relapse. ;) — Chase-san 00:46, 12 July 2011 (UTC)
- Don't worry. I just released a new version that lowered it's rank. :-P However, I am using a brand new drive and factor array system that are somewhat in their infancy (I really haven't given them enough shakedown yet, and a few bits are incomplete), so I do expect to climb back up into the top 50 eventually. I was at #49 at version 5.1.1. Still a long ways from the top, but just give me a little more time. :-) -- Skotty 00:57, 12 July 2011 (UTC)
- Yeah, you we're floating right below Seraphim, and thats why I say this. I have my pride, but her weak points are all the weak bots, her strong points are all the strong(er) robots. In perspective, she can defeats 3 (over 50% score only 2 if you use survival) robots in the top 10, but defeating robots in the top 10 does not get you high into the rankings. — Chase-san 01:22, 12 July 2011 (UTC)
Do you have any method of personal contact (E-mail, Messenger (AIM,Skype,Google Talk,Yahoo), IRC, Twitter), I wouldn't mind discussing things about robocode. — Chase-san 16:22, 12 July 2011 (UTC)
- I have an old AIM account, but I haven't been using it lately. If you are an active chat user, I could start firing it up on boot up again. Otherwise, I have an email account, but we need a secure way for me to send it to you that won't get picked up by spam bots. -- Skotty 03:01, 14 July 2011 (UTC)
Version 6.x Scores All Over The Map
Well...I'm officially confused. I've been seeing huge point swings against various opponents in the rumble even with minor changes, and it seems they are inconsistent with what I see at home. Though admittedly, I still need to put together a big stress test to get a larger performance sample. I'm still wondering if it may have something to do with missed turns, as I don't really know exactly what happens when a turn is missed (I can't find any docs that explain it thoroughly). Or maybe there are still exceptions happening. Or both, perhaps missed turns somehow causing exceptions. Hopefully I can figure it out because it is really driving me insane. Version 6.1.1 in the rumble actually lost a round to Barracuda, and that just doesn't happen. I'm going to try running v6.1.1 in the fast learning MC2K7 challenge tonight using RoboResearch, since that is already pretty much ready to go; not using any the Raiko stuff because I'm just doing it to see if any exceptions or other anomalies happen. Running 500 seasons, and will check on it in the morning. -- Skotty 06:07, 12 July 2011 (UTC)
- I think it is not help because roboresearch works with robocode version 1.6.4 and rr clients use robocode version 1.7.3 now and i notice, that there're some difference between them. If you want i can share little app, which may be called analogue of roboresearch with many restrictions, but it is designed to work with rc 1.7.3 --Jdev 08:14, 12 July 2011 (UTC)
- I have roboresearch working with 1.7.2.2 and have no problems with it. Don't see a reason why it shouldn't work with 1.7.3.0. --GrubbmGait 09:25, 12 July 2011 (UTC)
- As i remeber, RoboResearch requires modifications of robocode messages parser to work with last versions. But may be it was my unique troubles:) --Jdev 09:37, 12 July 2011 (UTC)
- You may be right, I did not get it from the source, but picked up a package of someone else (Voidious I think). --GrubbmGait 09:46, 12 July 2011 (UTC)
- As a note, this type of issue makes me wish that the roborumble client uploaded replay files when it uploaded results (Haha... that would take a lot of space). Actually... it would be nice even if it just uploaded skipped turn count along with the scores. --Rednaxela 12:22, 12 July 2011 (UTC)
- This morning it was up to 137 seasons of the MC2K7 fast learning challenge with no exceptions or anomalies. The skipped turns thing is still just a theory. Maybe I should intentionally make it run slower at home to try and cause some skipped turns to see what happens. On that same tangent, it is probably about time I worked on my robot's efficiency so that it isn't a potential issue. -- Skotty 12:45, 12 July 2011 (UTC)
- On the plus side, this whole thing has prompted me to finally build some nice CPU time profiling tools. Currently taking a closer look at how long various parts of the code take to execute. -- Skotty 13:44, 12 July 2011 (UTC)
- I'm still trying to figure out what the heck is going on. In version 6.1.2, the only change was to remove a debug print line that was in a bad place, causing part of the drive code to waste a couple of milliseconds when deciding where to go for a new wave. But check out the first battle result against nat.BlackHole 2.0gamma -- my survival went from 42.86 to 8.57 (difference from version 6.1.1 to version 6.1.2). I don't know if I am on the right track on trying to improve efficiency, but something is definitely still very wrong somewhere. I suppose I should try upgrading to the latest Robocode version and see what if any change that results in (I'm currently still using 1.7.2.2) -- Skotty 21:04, 12 July 2011 (UTC)
- Definitely use the rumble version to do ALL of your testing! It can make a big difference... You could be running into bugs in the old version or possibly in the new one.
- @Rednaxela, as usual you come up with interesting rumble ideas. I don't think storing a slug of data per bot would be unreasonable. Not every replay of course, but maybe a size-limited block of custom stats, exception reports, etc. The tricky part would be getting the rumble client to export it for the server, would probably require an API function. --Darkcanuck 21:40, 12 July 2011 (UTC)
New Theory on Performance Issues
I've been wondering if changing my robot to log exceptions to file is the reason for the performance anomalies. But I couldn't figure out how that would make sense until just now. Could it be that Robocode handles the following two situations differently (or perhaps, differently depending on Robocode version)?
- Robot run() method ends due to Exception
- Robot run() method ends normally
My new theory questions whether in some instances, a robot crashes but is reactivated to finish the remaining rounds, but in other instances it is out of commission for all remaining rounds. Before I added the code to log exceptions to disk, exceptions were not caught. Now they are caught, but they are caught outside of the main while() loop, causing the run method to exit without an exception. Without knowing how Robocode internally handles the robot threads, it is hard to say what effect this might have. -- Skotty 21:51, 12 July 2011 (UTC)
- It's been awhile, but I think that if the run() method exits, then your robot is done for the round! Doesn't robocode only call that once at the beginning of each round? You definitely want to catch and handle exceptions inside the loop so that your robot can keep playing, if possible. My bots use a while(true) loop inside run() and will never exit, except for an unhandled exception. --Darkcanuck 22:20, 12 July 2011 (UTC)
- The alternative is to do a try/catch inside the while() loop. And while this would help, it would also help mask Exceptions that happen. So on one hand, I want to handle them, but on the other, it's almost better for it to crash, burn, and throw a tantrum so I will actually see the problem and correct it, rather than having it erode my robots scores quietly. -- Skotty 22:33, 12 July 2011 (UTC)
Debugging XanderCat -- What Next?
I had at least one instance where XanderCat bugged out that ran on my own machine, but no exception report was produced (see XanderCat 6.1.4 vs MagicD3 0.41). This means it wasn't a runaway while loop. My next step is to start writing out short data files for every robot, every round. Then at the end of the battle, if everything went normally, the files will be deleted. In those files, I will write out the number of bullets I fired, and the number of bullets the opponent fired, my round hit ratio, and the absolute distance I traveled during the round. When I see a battle that went bonkers, here are the scenarios I will be looking for:
- Files present for some but not all rounds. This will indicate that the robot stopped operating completely.
- Files for all rounds present, but bullets I fired dropped dramatically or went to 0 at same point during the battle. This will indicate that my gun stopped firing.
- Files for all rounds present, but my hit ratio dropped dramatically or went to 0 at some point during the battle. This will indicate that my gun was firing but the aim went bonkers.
- Files for all rounds present, but the number of bullets opponent fired dropped dramatically or went to 0 at some point during the battle. This will indicate I stopped detecting the opponent's fired bullets.
- Files for all rounds present, but absolute distance travelled dropped dramatically or went to 0 at some point during the battle. This will indicate that my drive stopped working, and my robot just starting sitting still.
Anyone have any other suggestions as to what I might look for, or other ideas on how I might try to track this down? -- Skotty 13:32, 13 July 2011 (UTC)
What I've done is look at every single loop in my 4000+ lines of code, checking that each one has an exit clause, and if there isn't one hardcoding one in (using a countdown). I also put a try/catch around all my code so all my other code logs exceptions to disk. Otherwise, unless you have a security manager problem everything *should* be caught. In theory =) --Skilgannon 14:19, 13 July 2011 (UTC)
How about try the following: Set up a script that runs robocode repeatedly, with parameters that cause it to run XanderCat 6.1.4 vs MagicD3 0.41 AND save replay files, and have your script delete the replay file whenever the resulting score is above 50%? I've done command line scripting of battles before it's it's fairly trivial. I suggest this method because it should catch the problem in action regardless of the cause. --Rednaxela 14:34, 13 July 2011 (UTC)
- Switching to the most recent client for my testing was a good idea. Things are definitely different in version 1.7.3.0 than they were in 1.7.2.2. I think, for one, I have potentially fallen victim to a change in how Bullets are handled. My overall hit ratio in 1.7.3.0 keeps coming back 0, whereas it worked fine in 1.7.2.2. I have to look into it more, but I think it has to do with how I am handling the Bullets. I vaguely recall once seeing some Robocode issue related to Bullets, but I don't recall where at the moment. I'll have to dig into it more... -- Skotty 21:29, 13 July 2011 (UTC)
- Here it is: bullet.equals semantic has been change in 1.7.3.0 version - ID: 3312402. This is likely the root of all evil in my 6.x series of robots. I guess I can't trust on matching bullets by the actual Bullet objects. I will have to come up with some other way to keep track of them. After doing this, I bet all my other troubles will fade away. Note that the issue says it is fixed, but it doesn't really say in what version it is fixed (was it broken in 1.7.3.0, fixed in 1.7.3.0, then re-released as 1.7.3.0, or is it fixed in the source tree but we won't see it until 1.7.3.1 or whatever the next version is?). If it is supposed to be fixed in 1.7.3.0, then I would bet the equals() method was changed without also adding or updating the hashcode() method, ultimately breaking the hashcode() contract that states: "If two objects are equal according to the equals(Object) method, then calling the hashCode method on each of the two objects must produce the same integer result." I say this because I was using Bullet objects as keys in HashMaps. If hashcode() isn't right, this would cause a HashMap lookup to fail when equals() does not. -- Skotty 21:34, 13 July 2011 (UTC)
- What this bug means for XanderCat, is that all the gun hit ratios are broken. The gun used is selected by the hit ratio. I give bias so that XanderCat prefers the guess factor gun, so the guess factor gun is probably still getting selected most of the time, but at other times, it probably does crazy things like selecting the linear gun and only the linear gun for the entire duration of a battle. I don't know that for sure, but it's fairly likely given the problem. -- Skotty 22:10, 13 July 2011 (UTC)
- Ahhh that. That bug was reported against 1.7.3.0, and the fix is in the source tree and it will be in 1.7.3.1. As far as I understand, robocode used to give identical bullet objects, but at some point it had to give different objects due to architectural changes. The fix to 3312402 was implementing equals(). Oh, and hashcode() is also properly implemented, I checked (that was added 2 days after equals() was, both shortly after 1.7.3.0). --Rednaxela 22:09, 13 July 2011 (UTC)--Rednaxela 22:09, 13 July 2011 (UTC)
- Here it is: bullet.equals semantic has been change in 1.7.3.0 version - ID: 3312402. This is likely the root of all evil in my 6.x series of robots. I guess I can't trust on matching bullets by the actual Bullet objects. I will have to come up with some other way to keep track of them. After doing this, I bet all my other troubles will fade away. Note that the issue says it is fixed, but it doesn't really say in what version it is fixed (was it broken in 1.7.3.0, fixed in 1.7.3.0, then re-released as 1.7.3.0, or is it fixed in the source tree but we won't see it until 1.7.3.1 or whatever the next version is?). If it is supposed to be fixed in 1.7.3.0, then I would bet the equals() method was changed without also adding or updating the hashcode() method, ultimately breaking the hashcode() contract that states: "If two objects are equal according to the equals(Object) method, then calling the hashCode method on each of the two objects must produce the same integer result." I say this because I was using Bullet objects as keys in HashMaps. If hashcode() isn't right, this would cause a HashMap lookup to fail when equals() does not. -- Skotty 21:34, 13 July 2011 (UTC)
Empty Output Files
Anyone else ever have trouble with an output file being empty? I've had a lot of cases where I try to write something to a file in Robocode, where the file gets created, but it is empty and nothing gets written to it. Here is the end of my run() method (see below), that should write Exceptions to file. It usually works, but tonight I noticed I had an empty one. This was also happening with my diagnostic output files.
} catch (Exception e) {
File exceptionFile = getDataFile(getName().split(" ")[0] + "_Exception.txt");
log.error("Fatal exception occurred.");
log.error("Writing stack trace to " + exceptionFile.getAbsolutePath());
RobocodeFileWriter writer = null;
try {
writer = new RobocodeFileWriter(exceptionFile);
String s = e.getClass().getName() + ": " + e.getMessage() + "\n";
writer.write(s);
log.error(s);
for (StackTraceElement ste : e.getStackTrace()) {
s = ste.toString() + "\n";
writer.write(s);
log.error(s);
}
writer.close();
} catch (IOException ioe) {
if (writer != null) {
try {
writer.close();
} catch (Exception ce) { }
}
}
}
I'm not sure at the moment if the file gets created when the RobocodeFileWriter gets created, or after the first call to write. But either way, how would the file end up being empty? I did not call flush(), and maybe I should, but it really shouldn't make any difference as long as close() gets called. I am also calling log.error(String) in there, which writes to System.out, but I wouldn't think that would cause any problems. I had this same problem with my diagnostic output files...sometimes they would have data in them, other times the files would be there but empty. Thoughts? -- Skotty 04:51, 14 July 2011 (UTC)
- One would think it would, but it is better to remove it as a possible factor by flushing it manually. If that doesn't work... well. To be honest I don't work with robocode File IO much. — Chase-san 04:57, 14 July 2011 (UTC)
- In addition to that, there is at least one more bug I have to find, as shown by this battle: XanderCat 6.1.7 vs MoxieBot 1.0. MoxieBot got almost no bullet damage, but won half the rounds. Had to be an exception or something there. :-( -- Skotty 05:01, 14 July 2011 (UTC)
- UPDATE: No exception on MoxieBot; was just due to MoxieBot using very good bullet shielding. -- Skotty 15:39, 14 September 2011 (UTC)
- In addition to that, there is at least one more bug I have to find, as shown by this battle: XanderCat 6.1.7 vs MoxieBot 1.0. MoxieBot got almost no bullet damage, but won half the rounds. Had to be an exception or something there. :-( -- Skotty 05:01, 14 July 2011 (UTC)
- It may just be that the file operations are happening too slowly due to the large number of files in the folder. My diagnostics I had in originally created a file for every round of a battle that had anomalous results. I didn't expect battles against every single robot to have anomalous results, but they did, so there are thousands of tiny files in the folder. XanderCat 6.1.7 slowly cleans up the old files, but it will take a while before they are all gone. Maybe after the number of files is back down to a reasonable number, it will start working normally again. -- Skotty 05:28, 14 July 2011 (UTC)
New Factor Array Idea
I have a new idea for handling factor arrays that I will be trying out soon. I've already implemented it, but haven't put it to the test yet. The idea is to start off all factor arrays with a set amount of "weight" already evenly (or close to evenly) spread within the factors. This total amount of weight in the factor array never changes. Instead, when a hit is logged, the total "weight" added by the hit is removed evenly across all factors such that the total weight in the array does not change. The weight is simply redistributed.
I'm interested to see how well it works, but at the same time, I am not very hopeful. The redistribution will act much like "rolling" (or "array decay", as I like to call it), but will only occur on an array when hits are logged to it. -- Skotty 03:46, 12 August 2011 (UTC)
- This provided no improvement in practice, and it just added more complexity, so I ditched it. -- Skotty 15:38, 2 September 2011 (UTC)
Next Plans -- XanderCat 9.x -- September, 2011
I haven't uncovered any serious bugs in my robot, but I do have a plan for where to go next.
- First, and perhaps foremost, is re-assessing what segmentation is used. Over the next few weeks I will be doing a lot of RoboResearch on various segmentation combinations. Perhaps I will find that one or more of my existing segmenters is problematic, or buggy. Perhaps I will find that I just need to switch a few segmenters. Whatever the case, I think this holds a lot of potential for improvement.
- Second, and I have to verify this, but I do not think I am currently using information on bullet-hit-bullet events to add data points to my drive data. I drop the waves, but I think I overlooked using the information in my drive (if I know the opponents aim, I can add a data point even though I didn't actually get hit). How helpful will this be? Well, it should help the robot learn a little faster, and that could be good for a small boost.
- Third, I may look into utilizing bullet shadow. This may require a modification in how I process waves though. It could lead to another small overhaul of part of my framework.
It looks like you attained your top 40 goal. Congrats!--AW 15:01, 12 September 2011 (UTC)
- Woot! Thank you! -- Skotty 18:12, 12 September 2011 (UTC)
Using bullet-hit-bullets to add surfing data gave me quite a boost. I refactored some of my code so that instead of logging hits I log bullets (robocode Bullet objects) and it made the whole thing take an extra 6 lines of code or so =) I even do this in my surfing minibot. --Skilgannon 06:01, 13 September 2011 (UTC)
- Take a peek at my code? Some of my drive code is still a little messy (due to playing with different ideas), but you may have noticed in my class AbstractFactorArrayProcessor, I don't do anything in the oppWaveHitBullet and myWaveHitBullet methods. I also need to start passing the actual Bullet to those methods. Regardless, it's good advice. I will put that at the top of my TODO list. -- Skotty 12:44, 13 September 2011 (UTC)
- I didn't actually, but you know what they say about great minds ;-) Seriously, this had a noticeable impact on my surfing abilities even a minibot level, so if you want some guaranteed score get onto it ASAP. --Skilgannon 13:25, 13 September 2011 (UTC)
- Just wanted to mention that a bulletHitBullet event has getX() and getY() metohds. Before I knew that, I thought adding this would be really hard, but you can basically use the same code that you use when the enemy hits you. (Remember not to log it in both the oppWaveHitBullet and the myWaveHitBullet methods)--AW 13:56, 13 September 2011 (UTC)
- I made this change. However, against my test bed of robots, the score increase was only 0.2 APS. This will probably translate to about 0.1 APS in the Rumble, based on how my test bed has related to it in the past. Could even be less, as I currently only run 10 seasons for my test bed. I'm pretty sure I implemented it correctly as it wasn't that complicated of a change. Would you have expected a more signficant change than that? -- Skotty 15:35, 14 September 2011 (UTC)
- Sorry I'm late, but congrats from me too. =) I think that would be about top 10 at the time when I joined. :-P As to your question, I would expect more of a gain than that, but maybe you'll see that in the rumble. Everything you learn from a BulletHitBullet is something you wouldn't have learned until you actually got hit by a bullet. I remember being surprised by how much it gained when I added this to Komarious, but unfortunately it was right before the switchover to Darkcanuck's server and the score diff is lost forever... --Voidious 16:01, 14 September 2011 (UTC)
- Guess I should go back over it with a fine toothed comb and make sure I didn't make any mistakes. I'd hate to miss out on a big jump in score. :-) -- Skotty 16:28, 14 September 2011 (UTC)
- Sorry I'm late, but congrats from me too. =) I think that would be about top 10 at the time when I joined. :-P As to your question, I would expect more of a gain than that, but maybe you'll see that in the rumble. Everything you learn from a BulletHitBullet is something you wouldn't have learned until you actually got hit by a bullet. I remember being surprised by how much it gained when I added this to Komarious, but unfortunately it was right before the switchover to Darkcanuck's server and the score diff is lost forever... --Voidious 16:01, 14 September 2011 (UTC)
New Segmenter
I may have struck a little gold in some testing tonight. I decided to try out a new segmenter, and initial results against my current test bed are surprisingly good. Maybe a big part of my problem is not bugs I can't find, but things like not having the right segmenters yet. The new segmenter will see action in version 9.0 of XanderCat, which I expect to have done on or before this weekend. -- Skotty 01:37, 9 September 2011 (UTC)
Version 9.5 - Interesting Results
Version 9.5 included switching to using my data from time-2 for opponent waves, and a first run of surfing multiple waves. The results were interesting.
First off, something weird happened against YersiniaPestis 3.0 on darkcanuck's server. I highly doubt the 2 scores of 90 against it are legit. That would be vudu magic.
Scores in general are more varied than in previous versions, but that could just be because there are not enough battles yet. So far scores against Barracuda and HawkOnFire are up, which can be credited to the second wave surfing.
I'm seeing a few skipped turns for the first time ever. That is due to the extra processing required to do the second wave processing. I need to go back and see if I can make it more efficient now. I also haven't fine tuned the second wave processing, so there could be some more points to pick up there.
I had played with rolling drive data with some mixed results before releasing this version. However, for this version, I decided to continue not rolling any data. I need to do more analysis on this before I try to change it (or even if). —Preceding unsigned comment added by Skotty (talk • contribs)
- One cool speed optimization for multi-wave surfing, which I think Krabb taught me: After calculating the danger on the first wave, don't bother calculating second wave dangers for that movement option if the first wave danger is already higher than the best danger you've calculated so far. (Sounds obvious now... =)) If you also calculate the safest movement option from last tick first, that helps even more. Overall it's a really nice speed increase with no change to behavior. --Voidious 15:11, 20 September 2011 (UTC)
- Yep, this optimization is the only thing that stops DrussGT from falling over flat. I first do all my first-wave predictions, then sort them in ascending danger. As I go through, once I get a first wave danger that is higher than my lowest first+second wave danger I know I can immediately quit because the dangers will only be higher after that. Brilliant solution. Another thought is that you might want to play with the weighting of the different waves - I found that inverse time-till-hit worked quite well. Waves that are closer are higher priority, and waves that are further away can be dealt with, for the most part, later. --Skilgannon 06:02, 22 September 2011 (UTC)
- Just on a sidenote: dangers don't change if there is no new info, so you only have to recalculate them if new info is present (bullet hit, bullet hit bullet). You still have to determine the complete danger for f.e. multiwave, but that is just peanuts. But maybe I am just talking VCS and is DC a complete other situation. --GrubbmGait 08:56, 22 September 2011 (UTC)
- Nah, it's the same for other systems such as "DC" too. --Rednaxela 13:04, 22 September 2011 (UTC)
- Except that in my true surfing (and I suspect many others), waves are weighted by time to impact, which changes tick by tick. This is the big thing I'd grapple with if/when I try some go-to surfing. —Preceding unsigned comment added by Voidious (talk • contribs)
- Sorry, just to elaborate: You could, of course, cache the danger before applying time to impact. And, more conservatively, you could cache the precisely predicted locations that should be identical for whichever predicted path you moved along last tick. Historically, I've not done this because it seems ugly and error-prone, but I'm almost inclined now to give it a shot. --Voidious 14:41, 22 September 2011 (UTC)
- Well, to start with, I haven't done correct multi-wave surfing yet (still re-writing my movement) but I don't see why weighting waves by inverse time to hit could help except that it is more probable that your data on the waves that will hit later will be updated. Is there any other reason to weight the waves by time to hit if you are calculating all movement options for the second (or third etc.) wave?--AW 15:07, 22 September 2011 (UTC)
- The short answer is: I didn't think I needed to either when I first did my branching multi-wave surfing algorithm, but it performed better if I did. =) (I knew other bots weighted by time to impact.) But I can rationalize it. With True Surfing, each tick you're considering 2-3 movement options. When the two waves are 15 and 30 ticks away, it's unlikely that any of the 2-3 spots you're considering are where you'll finally end up - it's more of a "broad strokes" calculation to determine a direction, so considering both waves is important. As the first wave gets closer, it's more important to really decide which spot exactly on that wave you think is safest, and the second wave options for each of those spots are getting more and more similar anyway. When the nearest wave is only 3 ticks away, there is a ton of overlap on the second wave options. It's kind of silly to put a lot of weight on which 2-3 points come up for each of the second wave options - those same points might be reachable from any of your first wave options, meaning it's just random noise which ones happened to come up for each first wave option. --Voidious 15:18, 22 September 2011 (UTC)
- I can definitely see how it should help with that, but if your robot predicts every possible movement option, I would think that there is a better way to do this. To rephrase my idea, suppose you could see the enemy's bullets, then the safest movement option (or rather a safe movement option) would be where neither bullet would hit you. Now suppose the enemy fires waves with bullets of different powers at different angles and you could see these, the safest movement option would be the one that minimizes your damage. The assumption I am making is that if instead of multiple bullets at each angle you had an estimate of the probability he would shoot using any given angle this would still be the best possible movement option. I am pretty sure this is correct, but I need rednaxela to verify it. If this is the case, then the weighting of each wave should be based on the probability that your best estimate will change before the wave breaks.--AW 16:28, 22 September 2011 (UTC)
- I'm somewhat intrigued by what Skilgannon said. Bare in mind that XanderCat uses GoTo surfing. Right now, I start by picking a first and second choice on the first wave, then use those two points as starting points for the second wave. But I may have been more in a true surfing mindset when I set it up that way. Using Skilgannon's approach, I could consider a range of possibilities for the first wave, not just a first and second choice, ordered by danger and short-circuting second wave checks in the manner Skilgannon described. So long as I can keep it reasonably efficient, I'm willing to bet that will give me another performance boost. I'll have to experiment more with wave weighting as well. Right now, I weight the first and second waves equally regardless of their proximity, for much the same reasons as AW is speaking of, but I haven't really put a lot of thought into it yet. -- Skotty 20:23, 22 September 2011 (UTC)
- You really should consider the closest wave more dangerous, just like dodgeball. The first wave limits your range to move the most, while the second wave decides which direction to move if for the first wave the danger is almost the same on the whole range. Normally there is time to reach a reasonably safe spot when the second wave becomes the first wave, although it is true that the safest spot for the second wave can be out of reach because you had to dodge the first wave. Hmm, maybe I have to rethink my second-wave implementation, because currently it is just a first-wave calculation with a lower weighting. --GrubbmGait 21:18, 22 September 2011 (UTC)
- Another reason to weight the first wave higher is that it is certain that this is the information you will be surfing. When surfing the second wave as the new first wave (once the current first wave has passed) there will be a new second wave, so the stats will have changed. Because of this, although the second wave can certainly help with choosing where safe locations will be, there is a high probability that once you factor in the wave after it as well it will change quite a bit. Because of this, weighting the closer waves higher seems to help, or at least this is my thinking. Another thing that changes is distances - if the enemy robot moves right next to where your third wave safe points will be, that area is no longer as safe so the data you were surfing earlier is now useless.--Skilgannon 06:43, 23 September 2011 (UTC)
Melee Rumble
I finally started working on some components for the melee rumble. I was thinking I would add them as another scenario to XanderCat, but I'm not sure if I really want to add that extra bloat to it or not. I could release an entirely different robot for melee-only (same framework though). But I like the idea of adding it to XanderCat to expand on it's presence and multi-mode nature.
I finished a melee radar, and about half finished a melee gun. Still need to write a drive. My framework needed some minor adjustments to fully support melee combat, but nothing significant. It shouldn't be too long before I can put them to use.
Best Bot Page Candidate
I just wanted to say that I find your extensive information on how your built your bot and why to be an invaluable well of inspiration. If we had a reward for best bot page I would but XanderCat's up among the top. It might be the #1 even, I haven't looked around too much lately. Thanks! -- PEZ 09:40, 4 November 2011 (UTC)
- Thank you! I still feel it needs further improvement, but I have indeed put a lot of work into it. Parts of it are still in a state of semi-experimentation, and I do change things periodically. I try to keep the pages on the wiki up-to-date, but feel free to contact me if you have questions about some of the things that I have done, or if you are wondering if something I have written is still accurate, or if you just want to chat about design options or ideas. And welcome back! I'm happy to see you back in action! -- Skotty 01:23, 5 November 2011 (UTC)
KD-Tree
Are you using Red's 3rd generation tree found here. It uses parts from the dataStructures directory, so keep that in mind. — Chase-san 21:41, 1 December 2011 (UTC)